Haben Sie sich schon einmal über den Unterschied zwischen Web Crawling und Web Scraping gewundert? Damit sind Sie nicht allein. Diese Begriffe werden oft verwechselt, aber sie sind nicht dasselbe. Den Unterschied zu kennen ist entscheidend, insbesondere wenn Sie Daten von Websites abrufen möchten. In diesem Artikel werden wir Web-Crawling vs. Web-Scraping im Detail. Lassen Sie uns ohne weitere Umschweife loslegen.

Was ist Web Crawling und Web Scraping?
Hinter den Kulissen jeder Suchanfrage und jeder datenreichen Website verbirgt sich ein faszinierender Prozess, der Web-Crawling und Web-Scraping umfasst. Diese beiden integralen Komponenten arbeiten Hand in Hand, um zu navigieren und wertvolle Informationen zu extrahieren.
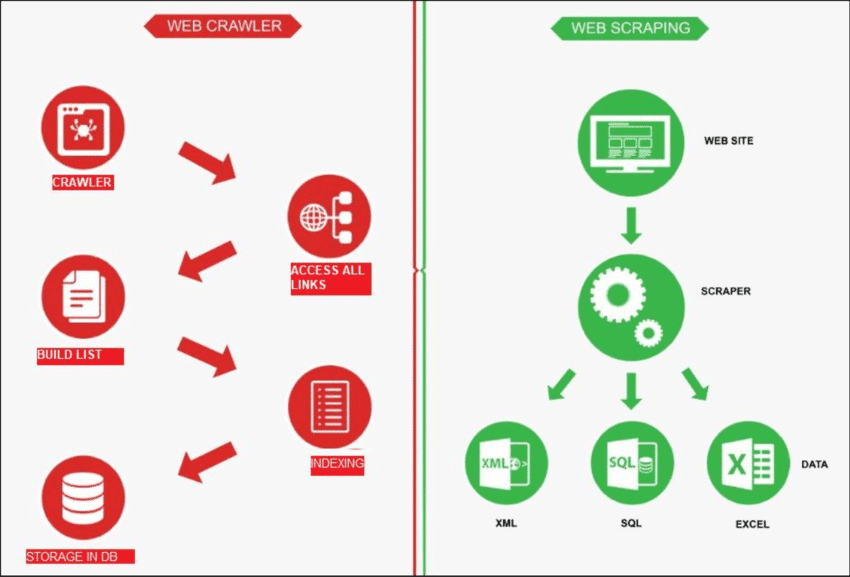
Quelle: ForschungsGate
Web-Crawling
Web-Crawling ist wie ein Roboter, der das Internet durchsucht, um neue Seiten finden. Seine Aufgabe ist es, eine Liste aller Seiten zu erstellen. Auf der anderen Seite ist Web Scraping wie das Verwenden einer Lupe auf bestimmten Websites, um Daten von bestimmten Seiten abrufen. Ein Webcrawler, auch Spider genannt, überprüft normalerweise zunächst einige Haupt-URLs einer bestimmten Site. Anschließend folgt er Links zu anderen Seiten, bis er alle gewünschten Seiten gefunden hat.
Das Webcrawling hat jedoch noch weitere Verwendungszwecke, z. B. das Erstellen einer Liste von Webseiten und das Überwachen von Änderungen an einer Site. Sowohl das Webcrawling als auch das Webscraping sind wichtig, wenn wir Informationen aus dem Web abrufen möchten.
Web Scraping
Web Scraping umfasst Abrufen von Daten von einer Zielwebsite, normalerweise mit automatisierten Tools, sogenannten Web Scrapern. Diese Tools lesen den HTML-Inhalt einer Webseite, um Informationen zu extrahieren.
Und so funktioniert es: Der Scraper stellt zunächst eine Verbindung zu den relevanten Webseiten her, die er durch einen Prozess namens Web-Crawling findet. Dort angekommen verwendet er Methoden wie CSS-Selektoren, um bestimmte HTML-Elemente und sammeln Sie die benötigten Daten.
Web Crawling vs. Web Scraping: Ein kurzer Blick
Vereinfacht ausgedrückt geht es beim Web-Crawling darum, Website-Links zu finden, und beim Web-Scraping darum, Daten von einer Website zu sammeln. Normalerweise erfordern die meisten Projekte, bei denen Informationen aus dem Web abgerufen werden, sowohl Crawling als auch Scraping.
| Besonderheit | Web-Crawling | Web Scraping |
|---|---|---|
| Zweck | Indizieren und Sammeln von Informationen aus dem Web | Extrahieren spezifischer Daten von Websites |
| Umfang | Indizieren und Sammeln von Informationen aus dem Web | Konzentriert sich auf bestimmte Seiten oder Inhalte innerhalb von Websites |
| Tiefe | Erkundet normalerweise die gesamte Website | Zielt auf bestimmte Daten innerhalb der Website ab |
| Frequenz | Regelmäßiges Crawlen zur Aktualisierung der Suchmaschinenindizes | Gelegentliche oder bedarfsweise Datenextraktion |
| Datenspeicherung | Speichert Metadaten, Links und Inhaltsindizes | Extrahiert und speichert bestimmte Datenpunkte |
| Techniken | Folgt Links, um Inhalte zu entdecken und zu indizieren | Nutzt HTML-Parsing, um spezifische Daten zu extrahieren |
| Beispiele | Suchmaschinen indizieren Webseiten für Suchergebnisse | Extrahieren von Produktpreisen von E-Commerce-Sites |
So funktioniert Web Scraping normalerweise:
✅ URLs entdecken: Durchsuchen Sie eine Site, um die Webseiten-Links zu finden.
✅ HTML herunterladen: Gehen Sie zu diesen Links und speichern Sie den Code der Website (HTML-Dateien).
✅ Daten scrapen: Analysieren Sie die HTML-Dateien und wählen Sie die Daten aus, die Sie benötigen.
Wenn eine Website also viele Seiten hat, werden diese zuerst durch Crawling gefunden, bevor die Daten gescrapt werden. Sehen wir uns nun den Unterschied zwischen Web Scraping und Web Crawling genauer an.
Verschiedene Anwendungsfälle von Web Crawling und Web Scraping
Web Scraping und Web Crawling sind separate Verfahren, die effektiv zusammenarbeiten können. Sie können je nach Aufgabe auch einzeln verwendet werden. Schauen wir uns die vielfältigen Anwendungsfälle dieser beiden Begriffe an.

Ressource: ScrapeHero
Web-Crawling: Häufigste Anwendungsfälle
Web-Crawling ist für Projekte nützlich, die eine Linksammlung benötigen, keine spezifischen Ziele haben und den Abruf des gesamten Seitencodes ohne zusätzliche Analyse erfordern. Häufige Anwendungsfälle sind:
1. Indizierung durch Suchmaschinen
- Google, Bing und Yahoo verwenden Crawler, um neue Inhalte und Seiten zu entdecken.
- Crawler speichern Informationen in einem Index, einer riesigen Datenbank zum Abrufen durch Benutzer.
2. Verbesserung der Site-Leistung
- Das Web-Crawling hilft bei der Analyse und Verbesserung der Leistung Ihrer Website.
- Erkennen Sie Probleme wie defekte Links, doppelte Inhalte oder Meta-Tag-Probleme.
- Identifiziert Möglichkeiten zur Optimierung der gesamten Sitestruktur.
3. Analyse der Website der Konkurrenz
- Überwachen Sie aus SEO-Gründen Änderungen auf Ihrer Website und auf den Websites Ihrer Mitbewerber.
- Bleiben Sie über Updates der Konkurrenz informiert und reagieren Sie umgehend.
4. Datengewinnung
- Webcrawler sammeln und analysieren große Datensätze aus verschiedenen Online-Quellen.
- Ermöglicht Forschern, Unternehmen und anderen, wertvolle Erkenntnisse zu gewinnen.
5. Auffinden defekter Links auf externen Websites
- Überprüfen und aktualisieren Sie die Links auf externen Websites, um die Richtigkeit sicherzustellen.
- Verwenden Sie Crawler, um die Überprüfung externer Links effizient durchzuführen.
6. Inhaltskuratierung
- Crawler finden effizient inhaltsbezogene Themen für Unternehmen oder Einzelpersonen.
- Ermöglicht eine schnelle Kuratierung basierend auf bestimmten Kriterien wie Schlüsselwörtern oder Tags.
Web Scraping: Häufigste Anwendungsfälle
Im Gegensatz dazu ist Web Scraping nützlich, wenn Sie ein bestimmtes Ziel für die Datenextraktion haben. Es wird häufig für folgende Zwecke eingesetzt:
1. Preise verfolgen
- Ermöglicht die automatische Verfolgung von Produktpreisen auf E-Commerce-Sites.
- Ermöglicht einen schnellen Preisvergleich auf mehreren Online-Plattformen.
- Ermöglicht Unternehmen, in Echtzeit über Preisänderungen informiert zu bleiben.
2. Inhalte aggregieren
- Ermöglicht die Inhaltsaggregation durch Extrahieren relevanter Informationen aus mehreren Quellen.
- Optimiert die Inhaltserfassung durch Automatisierung der Datenerfassung von verschiedenen Webseiten.
- Hilft bei der Konsolidierung unterschiedlicher Inhalte und macht diese an einem zentralen Ort zugänglich.
3. Leads finden
- Identifiziert und extrahiert Kontaktinformationen und optimiert so den Prozess der Lead-Generierung.
- Automatisiert die Erfassung potenzieller Leads aus verschiedenen Online-Quellen.
- Schneller Abruf wertvoller Geschäftsdaten zur Identifizierung und Kontaktaufnahme mit potenziellen Kunden.
5. Soziale Medien studieren
- Extrahiert Benutzerkommentare und -stimmungen für die Stimmungsanalyse in sozialen Medien.
- Sammelt für Forschungszwecke Daten zu Trendthemen und beliebten Beiträgen.
- Sammelt Kennzahlen zur Benutzerinteraktion, um die Auswirkungen sozialer Medien zu verstehen.
6. Online-Reputation verwalten
- Überwachen und sammeln Sie Online-Erwähnungen, um einen positiven Online-Ruf zu verwalten und aufrechtzuerhalten.
- Extrahieren und analysieren Sie relevante Daten, die bei der Lösung potenzieller Reputationsprobleme hilfreich sind.
- Verfolgen und reagieren Sie auf Kundenfeedback für ein effektives Online-Reputationsmanagement.
Seien Sie sich der üblichen Herausforderungen beim Web Crawling und Web Scraping bewusst
Dennoch muss man beim Web Crawling im Vergleich zum Web Scraping gewisse Hürden überwinden. Die Komplexität dieser Herausforderungen variiert je nach Projektgröße und reicht von technischen Hindernissen wie langsamen Ladezeiten bis hin zu rechtlichen Aspekten im Zusammenhang mit Datenschutzgesetzen.
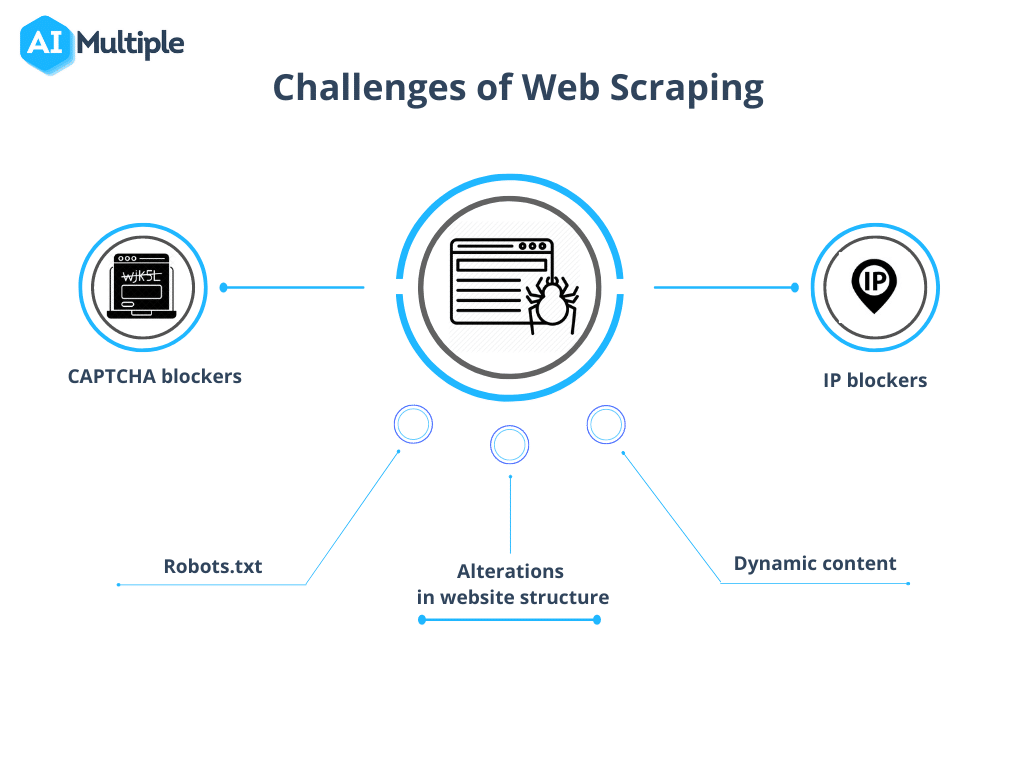
Quelle: KI-Multiple
1. Robots.txt blockiert Crawls
Bevor Sie mit dem Crawlen beginnen, müssen Sie unbedingt die Berechtigungen der Site bestätigen. Wenn in der robots.txt-Datei Einschränkungen für die Verwendung von Daten bestimmter Seiten angegeben sind, sollten Sie diese Bedingungen einhalten.
2. IP-Blockierung
Beim Crawlen ist es wichtig, Aktionen zu vermeiden, die menschliches Verhalten zu sehr nachahmen, da dies zu Misstrauen und IP-Blockierungen führen kann. Es wird empfohlen, eine kurze Verzögerung zwischen den Anfragen zu nutzen und Proxys zu verwenden, um die echte IP-Adresse zu maskieren. Es ist auch ratsam, einen Pool von Proxys zu durchlaufen.
3. Spinnenfallen
Bestimmte Ressourcen verwenden Crawler-Fallen, sogenannte Honeypots. Diese versteckten Links im Code, die für normale Benutzer unsichtbar sind, können dazu führen, dass ein Crawler sie erkennt und anschließend blockiert.
4. CAPTCHAs
Um Begegnungen mit CAPTCHAs, halten Sie sich an die oben genannten Richtlinien. Wenn CAPTCHAs unvermeidbar sind, sollten Sie die Nutzung von CAPTCHA-Lösungsdiensten in Betracht ziehen.
5. Überkriechen
Unsachgemäße Programmierung kann dazu führen, dass ein Bot in einer Endlosschleife hängen bleibt oder übermäßig crawlt, was die Zielwebsite übermäßig belastet. Dies kann den Zugriff für andere Benutzer stören, die Ressourcen der Site benötigen.
Fazit: Kennen Sie den Unterschied und arbeiten Sie entsprechend
Einfach ausgedrückt besteht das Ziel von Web Scraping darin, Informationen von Webseiten zu sammeln, während sich Web Crawling auf die Indizierung und Lokalisierung von Webseiten konzentriert. Web Crawling beinhaltet die kontinuierliche Erkundung von Links über Hyperlinks. Beim Web Scraping hingegen geht es um die Erstellung eines diskreten Programms, das Daten von verschiedenen Websites sammeln kann.
War dieser Blog hilfreich für Sie? Teilen Sie Ihre Gedanken mit, nehmen Sie an unserem Facebook-Community um mit anderen Enthusiasten in Kontakt zu treten und Abonnieren Sie unsere Blogs für weitere Blogs wie diesen.