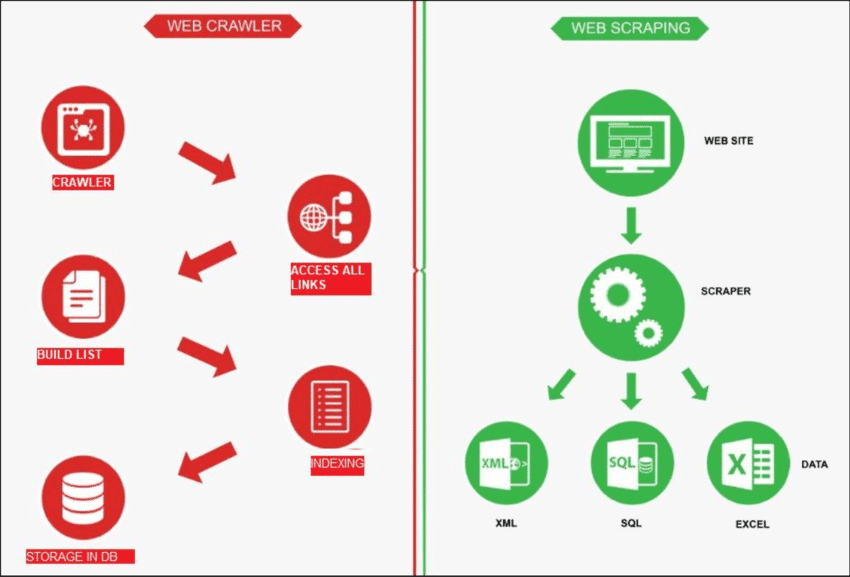
Ever wondered about the difference between web crawling and web scraping? You are not alone. These terms get mixed up a lot, but they are not the same. Knowing the distinction is key, especially if you are into pulling data from websites. In this article, we will break down web crawling vs web scraping in detail. Without any further ado, let us jump in.

What Is Web Crawling & Web Scraping?
Behind the scenes of every search query and data-rich website lies a fascinating process that involves web crawling and web scraping. These two integral components work hand-in-hand to navigate and extract valuable information.
Source: ResearchGate
Web Crawling
Web crawling is like a robot exploring the internet to find new pages. Its job is to make a list of all the pages out there. On the other hand, web scraping is like using a magnifying glass on specific sites to get data from certain pages. A web crawler, known as a spider, usually starts by checking out a few main URLs of a particular site. It then follows links to other pages until it has found all the pages it wants.
However, web crawling has different uses, such as making a list of web pages and keeping an eye on changes to a site. Both web crawling and web scraping are important when we want to grab information from the web.
Web Scraping
Web scraping involves pulling data from a target website, usually done with automated tools called web scrapers. These tools read the HTML content of a webpage to extract information.
Here’s how it works: the scraper first connects to the relevant web pages, which it finds through a process called web crawling. Once there, it uses methods like CSS selectors to pick specific HTML elements and gather the needed data.
Web Crawling vs Web Scraping: A Quick Glance
In simple terms, web crawling is about finding website links, and web scraping is about collecting data from a website. Typically, most projects involving getting information from the web require both crawling and scraping.
| Feature | Web Crawling | Web Scraping |
|---|---|---|
| Purpose | Indexing and gathering information from the web | Extracting specific data from websites |
| Scope | Indexing and gathering information from the web | Focuses on specific pages or content within websites |
| Depth | Typically explores the entire website | Targets specific data within the website |
| Frequency | Regularly crawls to update search engine indexes | Occasional or as-needed data extraction |
| Data Storage | Stores metadata, links, and content indices | Extracts and stores specific data points |
| Techniques | Follows links to discover and index content | Utilizes HTML parsing to extract specific data |
| Examples | Search engines indexing web pages for search results | Extracting product prices from e-commerce sites |
Here’s how web scraping usually works:
✅ Discover URLs: Look through a site to find the web page links.
✅ Download HTML: Go to those links and save the website’s code (HTML files).
✅ Scrape Data: Analyze the HTML files and pick out the data you need.
So, when a website has lots of pages, crawling comes first to find them before scraping the data. Now, let’s dive into a more detailed look at web scraping vs web crawling.
Different Use Cases Of Web Crawling & Web Scraping
Web scraping and web crawling are separate procedures that can work together effectively. They can also be used individually, depending on the job at hand. Let’s have a look at the multiple use cases of both these terms.

Resource: ScrapeHero
Web Crawling: Most Common Use Cases
Web crawling is useful for projects needing link collection, lacking specific targets, and requiring retrieval of entire page code without additional parsing. Common use cases include:
1. Search Engines Indexing
- Google, Bing, and Yahoo use crawlers to discover new content and pages.
- Crawlers store information in an index, a vast database for user retrieval.
2. Improving Site Performance
- Web crawling aids in analyzing and enhancing your website’s performance.
- Detect issues like broken links, duplicate content, or meta tag problems.
- Identifies opportunities for optimizing the overall site structure.
3. Competitor Website Analysis
- Monitor changes on both your and competitors’ websites for SEO purposes.
- Stay informed about competitors’ updates and react promptly.
4. Data Mining
- Web crawlers collect and analyze large data sets from various online sources.
- Facilitates researchers, businesses, or others in gaining valuable insights.
5. Finding Broken Links on External Sites
- Check and update links on external sites to maintain accuracy.
- Use crawlers to efficiently handle external link verification.
6. Content Curation
- Crawlers efficiently find content-related topics for businesses or individuals.
- Allows for quick curation based on specific criteria like keywords or tags.
Web Scraping: Most Common Use Cases
In contrast, web scraping is useful when you have a particular data extraction goal. It’s commonly applied for:
1. Tracking Prices
- Enables automated tracking of product prices on e-commerce sites.
- Facilitates quick comparison of prices across multiple online platforms.
- Allows businesses to stay informed about pricing changes in real time.
2. Aggregating Content
- Enables content aggregation by extracting relevant information from multiple sources.
- Streamlines content gathering by automating the collection of data from various web pages.
- Aids in consolidating diverse content, making it accessible in a centralized location.
3. Finding Leads
- Identifies and extracts contact information, streamlining the lead generation process.
- Automates the collection of potential leads from various online sources.
- Quick retrieval of valuable business data to identify and connect with potential clients.
5. Studying Social Media
- Extracts user comments and sentiments for social media sentiment analysis.
- Gathers data on trending topics and popular posts for research purposes.
- Collects user engagement metrics for understanding social media impact.
6. Managing Online Reputation
- Monitor and gather online mentions to manage and maintain a positive online reputation.
- Extract and analyze relevant data that helps to address potential reputation issues.
- Track and respond to customer feedback for effective online reputation management.
Be Aware Of Common Challenges Of Web Crawling & Web Scraping
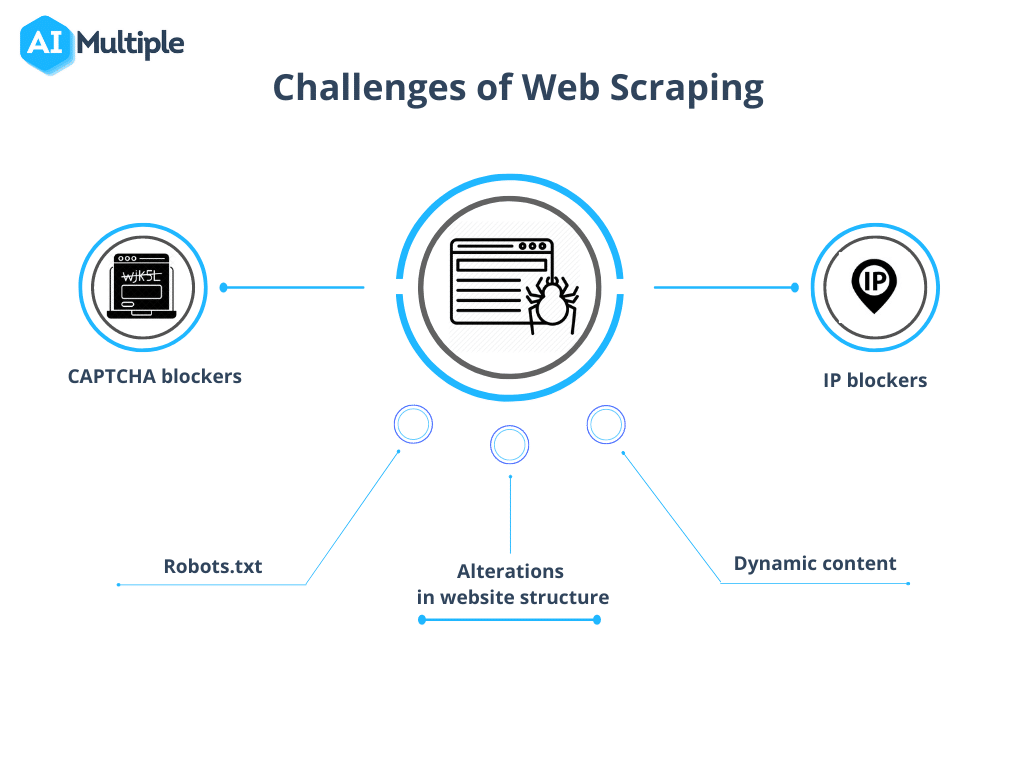
Nevertheless, web crawling vs web scraping has certain hurdles to deal with. The complexity of these challenges varies based on the project’s size, ranging from technical obstacles like slow loading times to legal considerations related to data privacy laws.
Source: AI Multiple
1. Robots.txt Blocking Crawls
Prior to initiating a crawl, it’s crucial to confirm the site’s permissions. If the robots.txt file indicates restrictions on using data from specific pages, it’s wise to respect these terms.
2. IP Blocking
While crawling, it’s essential to avoid actions that mimic human behavior too closely, as this may lead to suspicion and IP blocking. Utilizing a brief delay between requests and employing proxies to mask the real IP address is recommended. Rotating through a pool of proxies is also advisable.
3. Spider Traps
Certain resources employ crawler traps known as Honeypots. These hidden links in the code, invisible to regular users, can lead a crawler into detection and subsequent blocking.
4. CAPTCHAs
To minimize encounters with CAPTCHAs, adhere to the guidelines provided above. When CAPTCHAs are unavoidable, consider utilizing CAPTCHA-solving services.
5. Overcrawling
Improper programming may result in a bot getting stuck in an endless loop or excessively crawling, placing an undue load on the target website. This can disrupt access for other users needing resources from the site.
Bottom Line: Know The Difference And Work Accordingly
Simply put, the objective of web scraping is to gather information from web pages, while web crawling is focused on indexing and locating web pages. Web crawling entails the continuous exploration of links through hyperlinks. On the other hand, web scraping involves the creation of a discreet program capable of collecting data from various websites.
So, was this blog helpful for you? Share your thoughts, join our Facebook community to connect with fellow enthusiasts, and subscribe to our blogs for more blogs like this.