¿Alguna vez te preguntaste cuál es la diferencia entre el rastreo web y el raspado web? No eres el único. Estos términos se confunden mucho, pero no son lo mismo. Conocer la distinción es clave, especialmente si te dedicas a extraer datos de sitios web. En este artículo, analizaremos Rastreo web vs raspado web En detalle. Sin más preámbulos, vayamos al grano.

¿Qué es el rastreo web y el raspado web?
Detrás de cada consulta de búsqueda y de cada sitio web rico en datos se esconde un proceso fascinante que implica el rastreo y el raspado de la web. Estos dos componentes integrales trabajan en conjunto para navegar y extraer información valiosa.
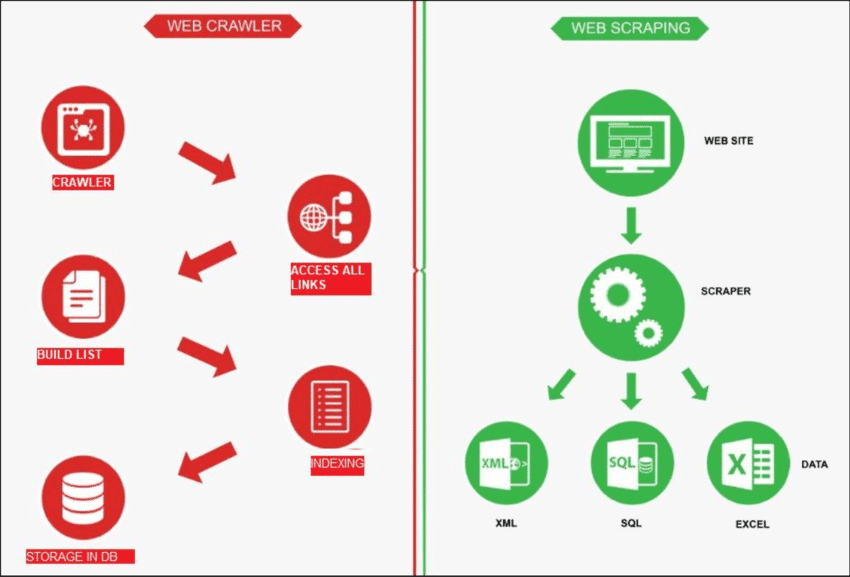
Fuente: Puerta de investigación
Rastreo web
El rastreo web es como un robot que explora Internet para... encontrar nuevas paginasSu función es hacer una lista de todas las páginas que hay. Por otro lado, el web scraping es como usar una lupa en sitios específicos para obtener datos de determinadas páginasUn rastreador web, conocido como araña, generalmente comienza por revisar algunas URL principales de un sitio en particular. Luego sigue los enlaces a otras páginas hasta que encuentra todas las páginas que desea.
Sin embargo, el rastreo web tiene diferentes usos, como por ejemplo, crear una lista de páginas web y controlar los cambios que se producen en un sitio. Tanto el rastreo web como el raspado web son importantes cuando queremos obtener información de la web.
Extracción de datos web
El web scraping implica Extraer datos de un sitio web de destino, que generalmente se realiza con herramientas automatizadas llamadas web scrapers. Estas herramientas leen el contenido HTML de una página web para extraer información.
Así es como funciona: el scraper primero se conecta a las páginas web relevantes, que encuentra a través de un proceso llamado rastreo web. Una vez allí, utiliza métodos como selectores CSS para seleccionar páginas específicas. Elementos HTML y recopilar los datos necesarios.
Rastreo web vs. raspado web: una mirada rápida
En términos simples, el rastreo web consiste en encontrar enlaces a sitios web, y el raspado web consiste en recopilar datos de un sitio web. Por lo general, la mayoría de los proyectos que implican obtener información de la web requieren tanto el rastreo como el raspado.
| Característica | Rastreo web | Extracción de datos web |
|---|---|---|
| Objetivo | Indexación y recopilación de información de la web | Extracción de datos específicos de sitios web |
| Alcance | Indexación y recopilación de información de la web | Se centra en páginas o contenidos específicos dentro de los sitios web. |
| Profundidad | Generalmente explora todo el sitio web. | Se dirige a datos específicos dentro del sitio web |
| Frecuencia | Se rastrea periódicamente para actualizar los índices de los motores de búsqueda. | Extracción de datos ocasional o según sea necesario |
| Almacenamiento de datos | Almacena metadatos, enlaces e índices de contenido. | Extrae y almacena puntos de datos específicos |
| Técnicas | Sigue enlaces para descubrir e indexar contenido. | Utiliza análisis HTML para extraer datos específicos |
| Ejemplos | Motores de búsqueda que indexan páginas web para obtener resultados de búsqueda | Extracción de precios de productos de sitios de comercio electrónico |
Así es como suele funcionar el web scraping:
✅ Descubra las URL: Busque en un sitio para encontrar los enlaces a las páginas web.
✅ Descargar HTML: Vaya a esos enlaces y guarde el código del sitio web (archivos HTML).
✅ Extraer datos: Analice los archivos HTML y seleccione los datos que necesita.
Entonces, cuando un sitio web tiene muchas páginas, primero se realiza el rastreo para encontrarlas antes de extraer los datos. Ahora, analicemos con más detalle la comparación entre el rastreo y el raspado web.
Diferentes casos de uso de rastreo y raspado web
El web scraping y el web crawling son procedimientos independientes que pueden funcionar juntos de manera eficaz. También se pueden utilizar de forma individual, según el trabajo en cuestión. Echemos un vistazo a los múltiples casos de uso de ambos términos.

Recurso: Héroe de Scrape
Rastreo web: casos de uso más comunes
El rastreo web es útil para proyectos que necesitan recopilar enlaces, carecen de objetivos específicos y requieren la recuperación del código de la página completa sin análisis adicional. Algunos casos de uso comunes incluyen:
1. Indexación de motores de búsqueda
- Google, Bing y Yahoo utilizan rastreadores para descubrir nuevos contenidos y páginas.
- Los rastreadores almacenan información en un índice, una vasta base de datos para la recuperación del usuario.
2. Mejorar el rendimiento del sitio
- El rastreo web ayuda a analizar y mejorar el rendimiento de su sitio web.
- Detecta problemas como enlaces rotos, contenido duplicado o problemas con metaetiquetas.
- Identifica oportunidades para optimizar la estructura general del sitio.
3. Análisis del sitio web de la competencia
- Monitoree los cambios en sus sitios web y en los de sus competidores con fines de SEO.
- Manténgase informado sobre las actualizaciones de los competidores y reaccione rápidamente.
4. Minería de datos
- Los rastreadores web recopilan y analizan grandes conjuntos de datos de diversas fuentes en línea.
- Facilita que investigadores, empresas y otros obtengan información valiosa.
5. Encontrar enlaces rotos en sitios externos
- Verifique y actualice los enlaces en sitios externos para mantener la precisión.
- Utilice rastreadores para gestionar de manera eficiente la verificación de enlaces externos.
6. Curación de contenidos
- Los rastreadores encuentran de manera eficiente temas de contenido relacionados para empresas o individuos.
- Permite una curación rápida basada en criterios específicos, como palabras clave o etiquetas.
Web Scraping: casos de uso más comunes
Por el contrario, el web scraping es útil cuando se tiene un objetivo de extracción de datos en particular. Se suele aplicar para:
1. Seguimiento de precios
- Permite el seguimiento automatizado de los precios de los productos en sitios de comercio electrónico.
- Facilita la comparación rápida de precios en múltiples plataformas en línea.
- Permite a las empresas mantenerse informadas sobre los cambios de precios en tiempo real.
2. Agregación de contenido
- Permite la agregación de contenido extrayendo información relevante de múltiples fuentes.
- Agiliza la recopilación de contenido al automatizar la recopilación de datos de varias páginas web.
- Ayuda a consolidar contenido diverso, haciéndolo accesible en una ubicación centralizada.
3. Encontrar clientes potenciales
- Identifica y extrae información de contacto, agilizando el proceso de generación de clientes potenciales.
- Automatiza la recopilación de clientes potenciales de varias fuentes en línea.
- Recuperación rápida de datos comerciales valiosos para identificar y conectar con clientes potenciales.
5. Estudiar las redes sociales
- Extrae comentarios y sentimientos de los usuarios para el análisis de sentimientos en las redes sociales.
- Recopila datos sobre temas de tendencia y publicaciones populares para fines de investigación.
- Recopila métricas de participación del usuario para comprender el impacto de las redes sociales.
6. Gestión de la reputación online
- Monitorear y recopilar menciones en línea para gestionar y mantener una reputación en línea positiva.
- Extraer y analizar datos relevantes que ayuden a abordar posibles problemas de reputación.
- Realice un seguimiento y responda a los comentarios de los clientes para una gestión eficaz de la reputación en línea.
Tenga en cuenta los desafíos comunes del rastreo y el raspado web
Sin embargo, el rastreo web frente al raspado web tiene ciertos obstáculos que afrontar. La complejidad de estos desafíos varía según el tamaño del proyecto y abarca desde obstáculos técnicos como tiempos de carga lentos hasta consideraciones legales relacionadas con las leyes de privacidad de datos.
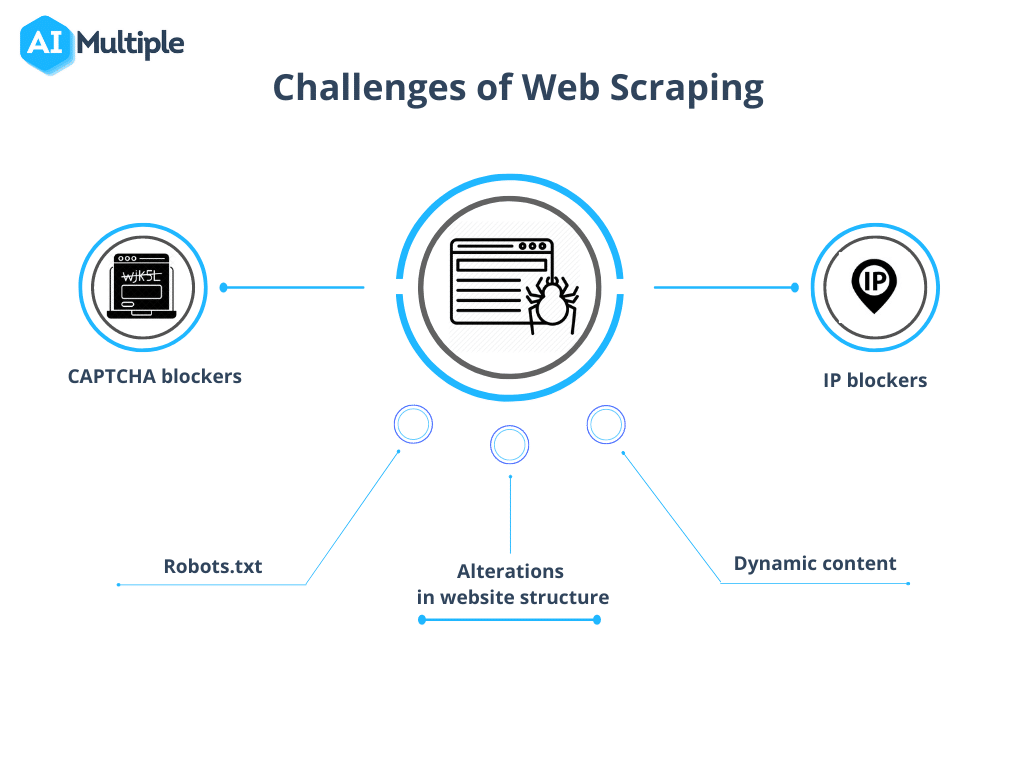
Fuente: IA Múltiple
1. Bloqueo de rastreos de robots.txt
Antes de iniciar un rastreo, es fundamental confirmar los permisos del sitio. Si el archivo robots.txt indica restricciones sobre el uso de datos de páginas específicas, es recomendable respetar estos términos.
2. Bloqueo de IP
Durante el rastreo, es fundamental evitar acciones que imiten demasiado el comportamiento humano, ya que esto puede generar sospechas y bloqueo de IP. Se recomienda utilizar un breve retraso entre las solicitudes y emplear servidores proxy para ocultar la dirección IP real. También es aconsejable rotar entre un grupo de servidores proxy.
3. Trampas para arañas
Algunos recursos emplean trampas para rastreadores conocidas como honeypots. Estos enlaces ocultos en el código, invisibles para los usuarios habituales, pueden hacer que un rastreador los detecte y los bloquee posteriormente.
4. CAPTCHA
Para minimizar los encuentros con CAPTCHA, respete las pautas proporcionadas anteriormente. Cuando los CAPTCHA sean inevitables, considere utilizar servicios de resolución de CAPTCHA.
5. Sobreexploración
Una programación incorrecta puede provocar que un bot se quede atascado en un bucle sin fin o que realice búsquedas excesivas, lo que supone una carga excesiva para el sitio web de destino. Esto puede interrumpir el acceso a otros usuarios que necesiten recursos del sitio.
En resumen: conozca la diferencia y trabaje en consecuencia
En términos simples, el objetivo del web scraping es recopilar información de las páginas web, mientras que el web crawling se centra en indexar y localizar páginas web. El web crawling implica la exploración continua de enlaces a través de hipervínculos. Por otro lado, el web scraping implica la creación de un programa discreto capaz de recopilar datos de varios sitios web.
Entonces, ¿este blog te resultó útil? Comparte tu opinión, únete a nuestro grupo. Comunidad de Facebook para conectarse con otros entusiastas y Suscríbete a nuestros blogs para más blogs como este.