Vous êtes-vous déjà demandé quelle était la différence entre l'exploration Web et le scraping Web ? Vous n'êtes pas le seul. Ces termes sont souvent confondus, mais ils ne sont pas identiques. Il est essentiel de connaître la distinction, surtout si vous souhaitez extraire des données de sites Web. Dans cet article, nous allons les décomposer. exploration du Web et scraping du Web en détail. Sans plus attendre, entrons dans le vif du sujet.

Qu'est-ce que le Web Crawling et le Web Scraping ?
Derrière chaque requête de recherche et chaque site Web riche en données se cache un processus fascinant qui implique l'exploration et le scraping du Web. Ces deux composants essentiels fonctionnent main dans la main pour naviguer et extraire des informations précieuses.
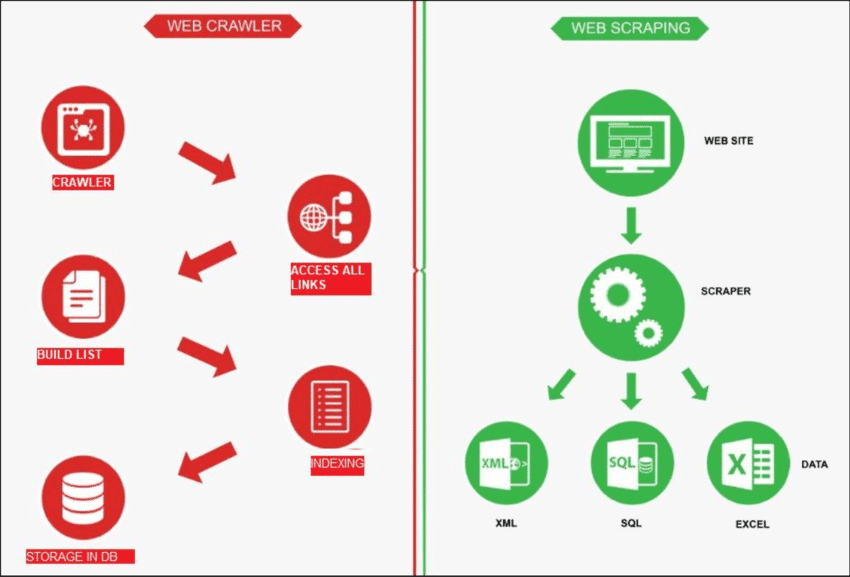
Source: RechercheGate
Exploration Web
L'exploration Web est comme un robot qui explore Internet pour trouver de nouvelles pages. Son travail consiste à établir une liste de toutes les pages existantes. D'autre part, le scraping Web consiste à utiliser une loupe sur des sites spécifiques pour obtenir des données à partir de certaines pages. Un robot d'exploration Web, appelé spider, commence généralement par vérifier quelques URL principales d'un site particulier. Il suit ensuite les liens vers d'autres pages jusqu'à ce qu'il ait trouvé toutes les pages qu'il souhaite.
Cependant, l'exploration Web a des utilisations différentes, comme créer une liste de pages Web et surveiller les modifications apportées à un site. L'exploration Web et le scraping Web sont tous deux importants lorsque nous voulons extraire des informations du Web.
Grattage Web
Le scraping Web implique extraire des données d'un site Web cible, généralement effectué à l'aide d'outils automatisés appelés scrapers Web. Ces outils lisent le contenu HTML d'une page Web pour en extraire des informations.
Voici comment cela fonctionne : le scraper se connecte d'abord aux pages Web pertinentes, qu'il trouve grâce à un processus appelé exploration Web. Une fois sur place, il utilise des méthodes telles que les sélecteurs CSS pour sélectionner des pages spécifiques. Éléments HTML et rassembler les données nécessaires.
Web Crawling vs Web Scraping : un aperçu rapide
En termes simples, l'exploration Web consiste à trouver des liens vers des sites Web, tandis que le scraping Web consiste à collecter des données à partir d'un site Web. En règle générale, la plupart des projets impliquant l'obtention d'informations sur le Web nécessitent à la fois l'exploration et le scraping.
| Fonctionnalité | Exploration Web | Grattage Web |
|---|---|---|
| But | Indexation et collecte d'informations sur le Web | Extraire des données spécifiques à partir de sites Web |
| Portée | Indexation et collecte d'informations sur le Web | Se concentre sur des pages ou du contenu spécifiques au sein des sites Web |
| Profondeur | Explore généralement l'intégralité du site Web | Cible des données spécifiques au sein du site Web |
| Fréquence | Exploration régulière pour mettre à jour les index des moteurs de recherche | Extraction de données occasionnelle ou selon les besoins |
| Stockage des données | Stocke les métadonnées, les liens et les index de contenu | Extrait et stocke des points de données spécifiques |
| Techniques | Suivez les liens pour découvrir et indexer le contenu | Utilise l'analyse HTML pour extraire des données spécifiques |
| Exemples | Les moteurs de recherche indexent les pages Web pour les résultats de recherche | Extraction des prix des produits à partir de sites de commerce électronique |
Voici comment fonctionne généralement le scraping Web :
✅ Découvrir les URL : Parcourez un site pour trouver les liens des pages Web.
✅ Télécharger le HTML: Accédez à ces liens et enregistrez le code du site Web (fichiers HTML).
✅ Extraire les données : Analysez les fichiers HTML et sélectionnez les données dont vous avez besoin.
Ainsi, lorsqu'un site Web comporte de nombreuses pages, l'exploration est la première étape pour les trouver avant de récupérer les données. Examinons maintenant de plus près la différence entre le scraping et l'exploration Web.
Différents cas d'utilisation de l'exploration et du scraping Web
Le scraping et l'exploration Web sont des procédures distinctes qui peuvent fonctionner ensemble efficacement. Elles peuvent également être utilisées individuellement, en fonction de la tâche à accomplir. Examinons les multiples cas d'utilisation de ces deux termes.

Ressource: ScrapeHéros
Exploration Web : cas d'utilisation les plus courants
L'exploration Web est utile pour les projets nécessitant une collecte de liens, manquant de cibles spécifiques et nécessitant la récupération de l'intégralité du code de la page sans analyse supplémentaire. Les cas d'utilisation courants incluent :
1. Indexation des moteurs de recherche
- Google, Bing et Yahoo utilisent des robots d'exploration pour découvrir de nouveaux contenus et de nouvelles pages.
- Les robots d'exploration stockent les informations dans un index, une vaste base de données permettant aux utilisateurs de les récupérer.
2. Améliorer les performances du site
- L'exploration Web permet d'analyser et d'améliorer les performances de votre site Web.
- Détectez les problèmes tels que les liens rompus, le contenu dupliqué ou les problèmes de balises méta.
- Identifie les opportunités d’optimisation de la structure globale du site.
3. Analyse des sites Web concurrents
- Surveillez les changements sur votre site Web et ceux de vos concurrents à des fins de référencement.
- Restez informé des mises à jour des concurrents et réagissez rapidement.
4. Exploration de données
- Les robots d’exploration Web collectent et analysent de grands ensembles de données provenant de diverses sources en ligne.
- Permet aux chercheurs, aux entreprises ou à d’autres d’obtenir des informations précieuses.
5. Recherche de liens brisés sur des sites externes
- Vérifiez et mettez à jour les liens sur les sites externes pour maintenir leur exactitude.
- Utilisez des robots d'exploration pour gérer efficacement la vérification des liens externes.
6. Conservation du contenu
- Les robots d'exploration trouvent efficacement des sujets liés au contenu pour les entreprises ou les particuliers.
- Permet une sélection rapide en fonction de critères spécifiques tels que des mots-clés ou des tags.
Web Scraping : cas d'utilisation les plus courants
En revanche, le scraping Web est utile lorsque vous avez un objectif d'extraction de données particulier. Il est couramment utilisé pour :
1. Suivi des prix
- Permet le suivi automatisé des prix des produits sur les sites de commerce électronique.
- Facilite la comparaison rapide des prix sur plusieurs plateformes en ligne.
- Permet aux entreprises de rester informées des changements de prix en temps réel.
2. Agrégation de contenu
- Permet l'agrégation de contenu en extrayant des informations pertinentes de plusieurs sources.
- Optimise la collecte de contenu en automatisant la collecte de données à partir de diverses pages Web.
- Aide à consolider un contenu diversifié, le rendant accessible dans un emplacement centralisé.
3. Trouver des prospects
- Identifie et extrait les informations de contact, simplifiant ainsi le processus de génération de leads.
- Automatise la collecte de prospects potentiels à partir de diverses sources en ligne.
- Récupération rapide de données commerciales précieuses pour identifier et se connecter avec des clients potentiels.
5. Étudier les médias sociaux
- Extrait les commentaires et les sentiments des utilisateurs pour l'analyse des sentiments sur les réseaux sociaux.
- Collecte des données sur les sujets tendance et les publications populaires à des fins de recherche.
- Collecte des mesures d'engagement des utilisateurs pour comprendre l'impact des médias sociaux.
6. Gérer la réputation en ligne
- Surveillez et collectez les mentions en ligne pour gérer et maintenir une réputation en ligne positive.
- Extraire et analyser les données pertinentes qui aident à résoudre les problèmes potentiels de réputation.
- Suivez et répondez aux commentaires des clients pour une gestion efficace de la réputation en ligne.
Soyez conscient des défis courants liés à l'exploration et au scraping Web
Néanmoins, la comparaison entre l'exploration et le scraping Web présente certains obstacles à surmonter. La complexité de ces défis varie en fonction de la taille du projet, allant des obstacles techniques tels que les temps de chargement lents aux considérations juridiques liées aux lois sur la confidentialité des données.
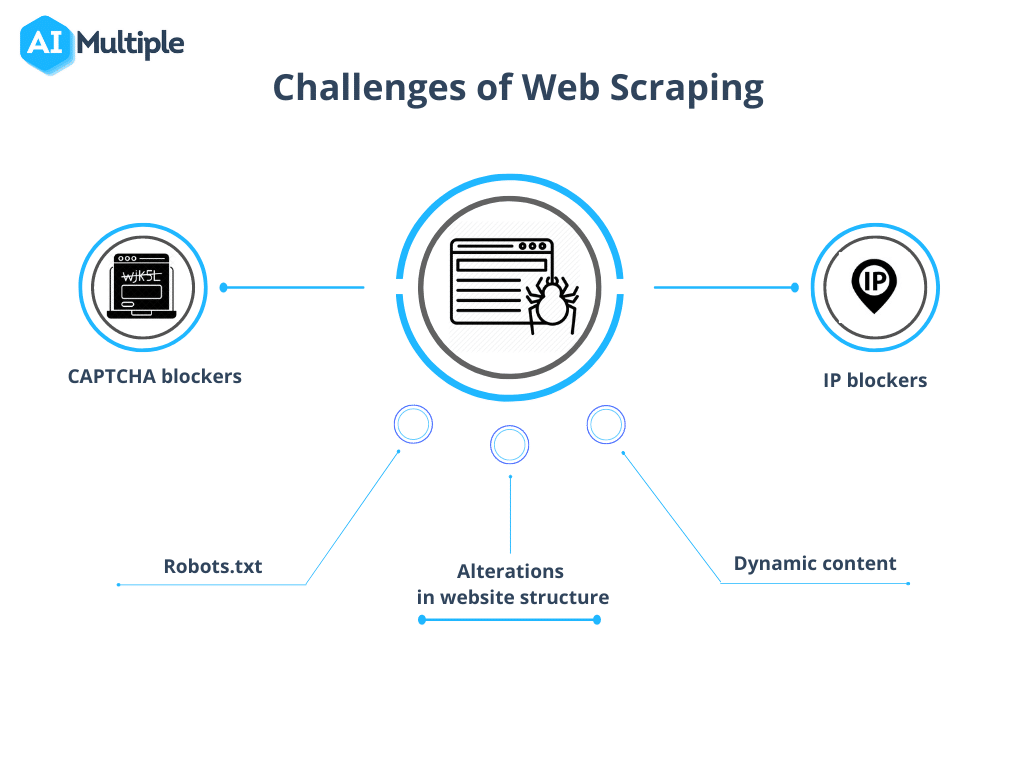
Source: IA multiple
1. Robots.txt bloque les crawls
Avant de lancer une exploration, il est essentiel de confirmer les autorisations du site. Si le fichier robots.txt indique des restrictions sur l'utilisation des données de pages spécifiques, il est judicieux de respecter ces conditions.
2. Blocage IP
Lors de l'exploration, il est essentiel d'éviter les actions qui imitent de trop près le comportement humain, car cela peut entraîner des soupçons et un blocage de l'IP. Il est recommandé d'utiliser un bref délai entre les requêtes et d'utiliser des proxys pour masquer l'adresse IP réelle. Il est également conseillé de faire tourner un pool de proxys.
3. Pièges à araignées
Certaines ressources utilisent des pièges d'exploration appelés Honeypots. Ces liens cachés dans le code, invisibles pour les utilisateurs ordinaires, peuvent conduire un robot à la détection et au blocage ultérieur.
4. CAPTCHA
Pour minimiser les rencontres avec CAPTCHA, respectez les consignes fournies ci-dessus. Lorsque les CAPTCHA sont inévitables, pensez à utiliser des services de résolution de CAPTCHA.
5. Surexploration
Une programmation incorrecte peut entraîner le blocage d'un robot dans une boucle sans fin ou une exploration excessive, ce qui impose une charge excessive au site Web cible. Cela peut perturber l'accès des autres utilisateurs ayant besoin des ressources du site.
En résumé : connaissez la différence et travaillez en conséquence
En termes simples, l'objectif du web scraping est de collecter des informations à partir de pages Web, tandis que le web crawling se concentre sur l'indexation et la localisation de pages Web. Le web crawling implique l'exploration continue de liens via des hyperliens. D'autre part, le web scraping implique la création d'un programme discret capable de collecter des données à partir de divers sites Web.
Alors, ce blog vous a-t-il été utile ? Partagez vos réflexions, rejoignez notre Communauté Facebook pour se connecter avec d'autres passionnés, et abonnez-vous à nos blogs pour plus de blogs comme celui-ci.