क्या आपने कभी वेब क्रॉलिंग और वेब स्क्रैपिंग के बीच के अंतर के बारे में सोचा है? आप अकेले नहीं हैं। ये शब्द अक्सर आपस में मिल जाते हैं, लेकिन ये एक जैसे नहीं हैं। इनके बीच का अंतर जानना बहुत ज़रूरी है, खासकर अगर आप वेबसाइट से डेटा खींच रहे हैं। इस लेख में, हम इनके बारे में विस्तार से बताएँगे वेब क्रॉलिंग बनाम वेब स्क्रैपिंग विस्तार से। बिना किसी देरी के, चलिए शुरू करते हैं।

वेब क्रॉलिंग और वेब स्क्रैपिंग क्या है?
हर खोज क्वेरी और डेटा-समृद्ध वेबसाइट के पीछे एक आकर्षक प्रक्रिया छिपी होती है जिसमें वेब क्रॉलिंग और वेब स्क्रैपिंग शामिल होती है। ये दो अभिन्न घटक नेविगेट करने और मूल्यवान जानकारी निकालने के लिए एक साथ काम करते हैं।
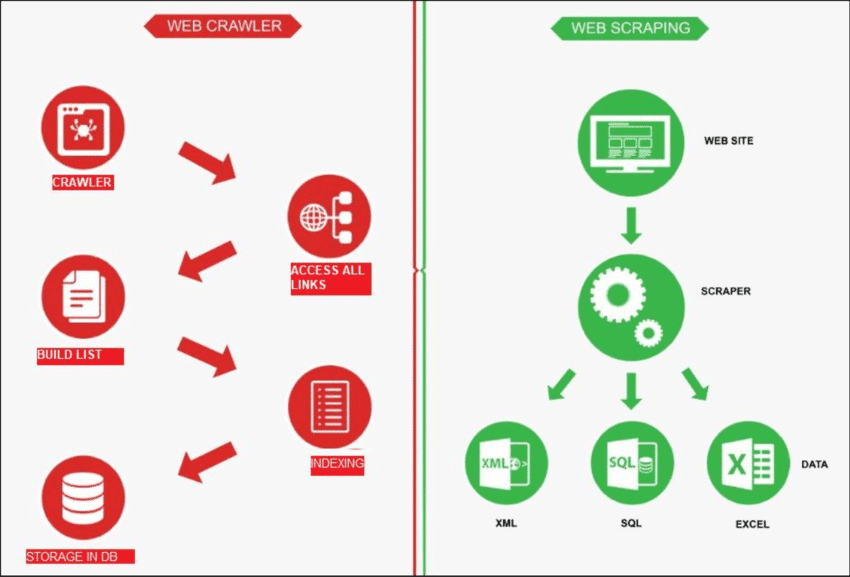
स्रोत: रिसर्चगेट
वेब क्रॉलिंग
वेब क्रॉलिंग एक रोबोट की तरह है जो इंटरनेट पर खोजबीन कर रहा है। नये पृष्ठ खोजेंइसका काम सभी पेजों की सूची बनाना है। दूसरी ओर, वेब स्क्रैपिंग किसी खास साइट पर आवर्धक कांच का उपयोग करने जैसा है। कुछ पृष्ठों से डेटा प्राप्त करेंवेब क्रॉलर, जिसे स्पाइडर के नाम से जाना जाता है, आमतौर पर किसी खास साइट के कुछ मुख्य URL की जांच करके शुरू करता है। फिर यह अन्य पेजों के लिंक का अनुसरण करता है जब तक कि उसे वे सभी पेज नहीं मिल जाते जो उसे चाहिए।
हालाँकि, वेब क्रॉलिंग के अलग-अलग उपयोग हैं, जैसे कि वेब पेजों की सूची बनाना और किसी साइट में होने वाले बदलावों पर नज़र रखना। जब हम वेब से जानकारी हासिल करना चाहते हैं तो वेब क्रॉलिंग और वेब स्क्रैपिंग दोनों ही महत्वपूर्ण हैं।
वेब स्क्रेपिंग
वेब स्क्रैपिंग में शामिल है लक्ष्य वेबसाइट से डेटा खींचना, आमतौर पर वेब स्क्रैपर्स नामक स्वचालित उपकरणों के साथ किया जाता है। ये उपकरण जानकारी निकालने के लिए वेबपेज की HTML सामग्री को पढ़ते हैं।
यह इस तरह काम करता है: स्क्रैपर सबसे पहले संबंधित वेब पेजों से जुड़ता है, जिसे वह वेब क्रॉलिंग नामक प्रक्रिया के माध्यम से खोजता है। वहां पहुंचने के बाद, यह विशिष्ट चुनने के लिए CSS चयनकर्ताओं जैसी विधियों का उपयोग करता है HTML तत्व और आवश्यक डेटा इकट्ठा करें.
वेब क्रॉलिंग बनाम वेब स्क्रैपिंग: एक त्वरित नज़र
सरल शब्दों में, वेब क्रॉलिंग का मतलब वेबसाइट लिंक ढूँढना है, और वेब स्क्रैपिंग का मतलब वेबसाइट से डेटा एकत्र करना है। आम तौर पर, वेब से जानकारी प्राप्त करने से जुड़ी ज़्यादातर परियोजनाओं में क्रॉलिंग और स्क्रैपिंग दोनों की ज़रूरत होती है।
| विशेषता | वेब क्रॉलिंग | वेब स्क्रेपिंग |
|---|---|---|
| उद्देश्य | वेब से सूचना को अनुक्रमित करना और एकत्रित करना | वेबसाइटों से विशिष्ट डेटा निकालना |
| दायरा | वेब से सूचना को अनुक्रमित करना और एकत्रित करना | वेबसाइटों के विशिष्ट पृष्ठों या सामग्री पर ध्यान केंद्रित करता है |
| गहराई | आमतौर पर पूरी वेबसाइट का अन्वेषण करता है | वेबसाइट के भीतर विशिष्ट डेटा को लक्षित करता है |
| आवृत्ति | खोज इंजन इंडेक्स को अपडेट करने के लिए नियमित रूप से क्रॉल करता है | कभी-कभी या आवश्यकतानुसार डेटा निष्कर्षण |
| आधार सामग्री भंडारण | मेटाडेटा, लिंक और सामग्री सूचकांक संग्रहीत करता है | विशिष्ट डेटा बिंदुओं को निकालता और संग्रहीत करता है |
| TECHNIQUES | सामग्री खोजने और अनुक्रमित करने के लिए लिंक का अनुसरण करता है | विशिष्ट डेटा निकालने के लिए HTML पार्सिंग का उपयोग करता है |
| उदाहरण | खोज इंजन खोज परिणामों के लिए वेब पृष्ठों को अनुक्रमित करते हैं | ई-कॉमर्स साइटों से उत्पाद की कीमतें निकालना |
वेब स्क्रैपिंग आमतौर पर इस प्रकार काम करती है:
✅ यूआरएल खोजें: वेब पेज लिंक ढूंढने के लिए किसी साइट को देखें।
✅ HTML डाउनलोड करें: उन लिंक पर जाएं और वेबसाइट का कोड (HTML फाइल) सेव करें।
✅ डेटा स्क्रैप करें: HTML फ़ाइलों का विश्लेषण करें और आवश्यक डेटा चुनें।
इसलिए, जब किसी वेबसाइट में बहुत सारे पेज होते हैं, तो डेटा को स्क्रैप करने से पहले उन्हें खोजने के लिए क्रॉलिंग सबसे पहले आती है। अब, आइए वेब स्क्रैपिंग बनाम वेब क्रॉलिंग पर अधिक विस्तृत नज़र डालें।
वेब क्रॉलिंग और वेब स्क्रैपिंग के विभिन्न उपयोग मामले
वेब स्क्रैपिंग और वेब क्रॉलिंग अलग-अलग प्रक्रियाएँ हैं जो एक साथ मिलकर प्रभावी ढंग से काम कर सकती हैं। काम के आधार पर इनका अलग-अलग इस्तेमाल भी किया जा सकता है। आइए इन दोनों शब्दों के कई उपयोगों पर नज़र डालें।

संसाधन: स्क्रैपहीरो
वेब क्रॉलिंग: सबसे आम उपयोग के मामले
वेब क्रॉलिंग उन परियोजनाओं के लिए उपयोगी है जिनमें लिंक संग्रह की आवश्यकता होती है, विशिष्ट लक्ष्यों की कमी होती है, और अतिरिक्त पार्सिंग के बिना पूरे पृष्ठ कोड की पुनर्प्राप्ति की आवश्यकता होती है। सामान्य उपयोग के मामलों में शामिल हैं:
1. खोज इंजन अनुक्रमण
- गूगल, बिंग और याहू नई सामग्री और पेज खोजने के लिए क्रॉलर का उपयोग करते हैं।
- क्रॉलर सूचना को एक इंडेक्स में संग्रहीत करते हैं, जो उपयोगकर्ता पुनर्प्राप्ति के लिए एक विशाल डाटाबेस होता है।
2. साइट प्रदर्शन में सुधार
- वेब क्रॉलिंग आपकी वेबसाइट के प्रदर्शन का विश्लेषण करने और उसे बढ़ाने में सहायता करती है।
- टूटे हुए लिंक, डुप्लिकेट सामग्री या मेटा टैग समस्याओं जैसी समस्याओं का पता लगाएं.
- समग्र साइट संरचना को अनुकूलित करने के अवसरों की पहचान करता है।
3. प्रतिस्पर्धी वेबसाइट विश्लेषण
- एसईओ प्रयोजनों के लिए अपनी और प्रतिस्पर्धियों की वेबसाइटों पर परिवर्तनों पर नज़र रखें।
- प्रतिस्पर्धियों के अपडेट के बारे में जानकारी रखें और तुरंत प्रतिक्रिया दें।
4. डेटा माइनिंग
- वेब क्रॉलर विभिन्न ऑनलाइन स्रोतों से बड़े डेटा सेट एकत्रित और उनका विश्लेषण करते हैं।
- शोधकर्ताओं, व्यवसायों या अन्य लोगों को मूल्यवान अंतर्दृष्टि प्राप्त करने में सुविधा प्रदान करता है।
5. बाहरी साइटों पर टूटे हुए लिंक ढूँढना
- सटीकता बनाए रखने के लिए बाहरी साइटों पर लिंक की जांच करें और उन्हें अपडेट करें।
- बाहरी लिंक सत्यापन को कुशलतापूर्वक संभालने के लिए क्रॉलर का उपयोग करें।
6. कंटेंट क्यूरेशन
- क्रॉलर व्यवसायों या व्यक्तियों के लिए सामग्री-संबंधित विषयों को कुशलतापूर्वक खोजते हैं।
- कीवर्ड या टैग जैसे विशिष्ट मानदंडों के आधार पर त्वरित क्यूरेशन की अनुमति देता है।
वेब स्क्रैपिंग: सबसे आम उपयोग के मामले
इसके विपरीत, वेब स्क्रैपिंग तब उपयोगी होती है जब आपका कोई खास डेटा निष्कर्षण लक्ष्य होता है। इसे आमतौर पर निम्न के लिए लागू किया जाता है:
1. कीमतों पर नज़र रखना
- ई-कॉमर्स साइटों पर उत्पाद की कीमतों की स्वचालित ट्रैकिंग सक्षम करता है।
- विभिन्न ऑनलाइन प्लेटफॉर्मों पर कीमतों की त्वरित तुलना की सुविधा प्रदान करता है।
- यह व्यवसायों को वास्तविक समय में मूल्य निर्धारण परिवर्तनों के बारे में सूचित रहने की अनुमति देता है।
2. सामग्री एकत्रित करना
- एकाधिक स्रोतों से प्रासंगिक जानकारी निकालकर सामग्री एकत्रीकरण को सक्षम बनाता है।
- विभिन्न वेब पृष्ठों से डेटा के संग्रहण को स्वचालित करके सामग्री एकत्रीकरण को सुव्यवस्थित करता है।
- विविध विषय-वस्तु को समेकित करने में सहायता करता है, जिससे इसे एक केंद्रीकृत स्थान पर सुलभ बनाया जा सके।
3. लीड ढूँढना
- संपर्क जानकारी की पहचान करना और उसे निकालना, लीड जनरेशन प्रक्रिया को सुव्यवस्थित करना।
- विभिन्न ऑनलाइन स्रोतों से संभावित लीड्स के संग्रह को स्वचालित करता है।
- संभावित ग्राहकों की पहचान करने और उनसे जुड़ने के लिए मूल्यवान व्यावसायिक डेटा की त्वरित पुनर्प्राप्ति।
5. सोशल मीडिया का अध्ययन
- सोशल मीडिया भावना विश्लेषण के लिए उपयोगकर्ता की टिप्पणियों और भावनाओं को निकालता है।
- अनुसंधान उद्देश्यों के लिए ट्रेंडिंग विषयों और लोकप्रिय पोस्ट पर डेटा एकत्र करता है।
- सोशल मीडिया प्रभाव को समझने के लिए उपयोगकर्ता सहभागिता मीट्रिक्स एकत्रित करता है।
6. ऑनलाइन प्रतिष्ठा का प्रबंधन
- सकारात्मक ऑनलाइन प्रतिष्ठा को प्रबंधित और बनाए रखने के लिए ऑनलाइन उल्लेखों की निगरानी करें और उन्हें एकत्रित करें।
- प्रासंगिक डेटा निकालें और उसका विश्लेषण करें जो संभावित प्रतिष्ठा संबंधी मुद्दों को हल करने में मदद करता है।
- प्रभावी ऑनलाइन प्रतिष्ठा प्रबंधन के लिए ग्राहक प्रतिक्रिया को ट्रैक करें और उसका जवाब दें।
वेब क्रॉलिंग और वेब स्क्रैपिंग की आम चुनौतियों से अवगत रहें
फिर भी, वेब क्रॉलिंग बनाम वेब स्क्रैपिंग में कुछ बाधाओं से निपटना पड़ता है। इन चुनौतियों की जटिलता परियोजना के आकार के आधार पर भिन्न होती है, जिसमें धीमी लोडिंग समय जैसी तकनीकी बाधाओं से लेकर डेटा गोपनीयता कानूनों से संबंधित कानूनी विचार शामिल हैं।
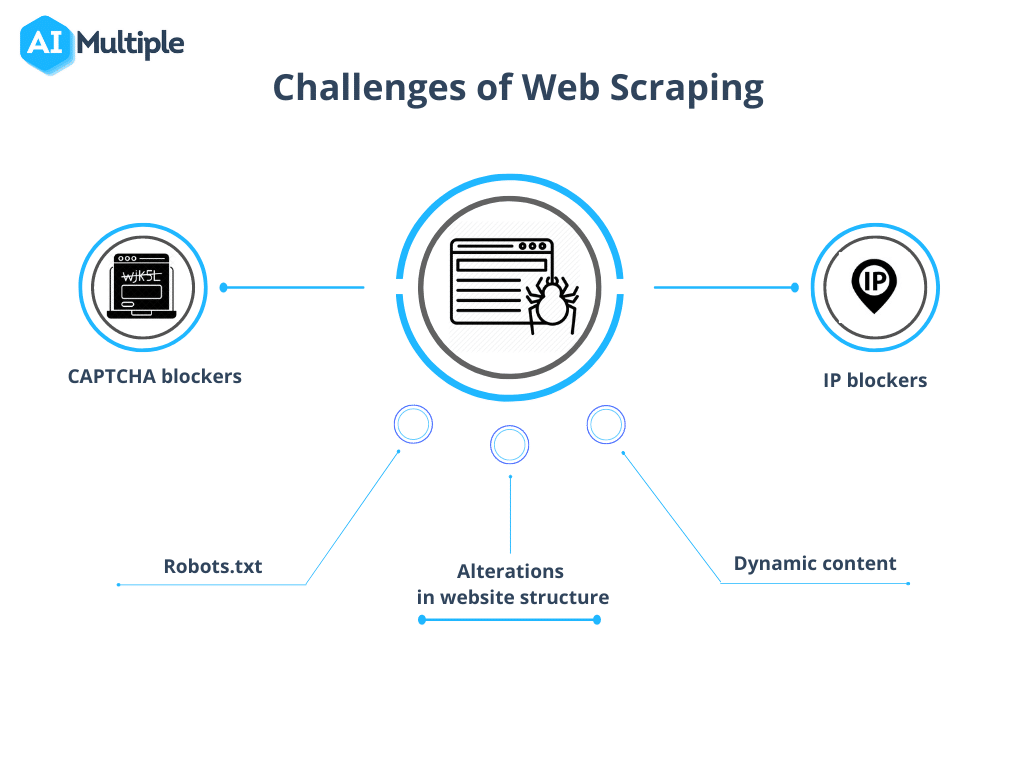
स्रोत: एआई मल्टीपल
1. Robots.txt क्रॉल को ब्लॉक करना
क्रॉल शुरू करने से पहले, साइट की अनुमतियों की पुष्टि करना महत्वपूर्ण है। अगर robots.txt फ़ाइल में खास पेजों से डेटा इस्तेमाल करने पर प्रतिबंध का संकेत मिलता है, तो इन शर्तों का सम्मान करना समझदारी है।
2. आईपी ब्लॉकिंग
क्रॉलिंग करते समय, मानव व्यवहार की बहुत बारीकी से नकल करने वाली क्रियाओं से बचना आवश्यक है, क्योंकि इससे संदेह और आईपी ब्लॉकिंग हो सकती है। अनुरोधों के बीच एक संक्षिप्त विलंब का उपयोग करना और वास्तविक आईपी पते को छिपाने के लिए प्रॉक्सी का उपयोग करना अनुशंसित है। प्रॉक्सी के पूल के माध्यम से घूमना भी उचित है।
3. मकड़ी जाल
कुछ संसाधन क्रॉलर ट्रैप का इस्तेमाल करते हैं जिन्हें हनीपोट्स के नाम से जाना जाता है। कोड में छिपे ये लिंक, जो नियमित उपयोगकर्ताओं के लिए अदृश्य होते हैं, क्रॉलर को पता लगाने और बाद में ब्लॉक करने की ओर ले जा सकते हैं।
4. कैप्चा
मुठभेड़ों को कम करने के लिए कैप्चा, ऊपर दिए गए दिशा-निर्देशों का पालन करें। जब CAPTCHAs अपरिहार्य हों, तो CAPTCHA-समाधान सेवाओं का उपयोग करने पर विचार करें।
5. ओवरक्रॉलिंग
अनुचित प्रोग्रामिंग के कारण बॉट अंतहीन लूप में फंस सकता है या अत्यधिक क्रॉलिंग कर सकता है, जिससे लक्षित वेबसाइट पर अनावश्यक लोड पड़ सकता है। इससे साइट से संसाधनों की आवश्यकता वाले अन्य उपयोगकर्ताओं की पहुँच बाधित हो सकती है।
निष्कर्ष: अंतर को जानें और उसके अनुसार काम करें
सीधे शब्दों में कहें तो वेब स्क्रैपिंग का उद्देश्य वेब पेजों से जानकारी एकत्र करना है, जबकि वेब क्रॉलिंग का उद्देश्य वेब पेजों को अनुक्रमित करना और उनका पता लगाना है। वेब क्रॉलिंग में हाइपरलिंक के माध्यम से लिंक की निरंतर खोज शामिल है। दूसरी ओर, वेब स्क्रैपिंग में विभिन्न वेबसाइटों से डेटा एकत्र करने में सक्षम एक विवेकपूर्ण प्रोग्राम का निर्माण शामिल है।
तो, क्या यह ब्लॉग आपके लिए मददगार था? अपने विचार साझा करें, हमारे साथ जुड़ें फेसबुक समुदाय साथी उत्साही लोगों से जुड़ने के लिए, और हमारे ब्लॉग की सदस्यता लें इस तरह के और अधिक ब्लॉग के लिए.