Ti sei mai chiesto qual è la differenza tra web crawling e web scraping? Non sei il solo. Questi termini vengono spesso confusi, ma non sono la stessa cosa. Conoscere la distinzione è fondamentale, soprattutto se ti occupi di estrarre dati dai siti web. In questo articolo, analizzeremo web crawling contro web scraping in dettaglio. Senza ulteriori indugi, entriamo nel vivo.

Cosa sono il Web Crawling e il Web Scraping?
Dietro le quinte di ogni query di ricerca e di ogni sito web ricco di dati si cela un affascinante processo che coinvolge il web crawling e il web scraping. Questi due componenti integrali lavorano a stretto contatto per navigare ed estrarre informazioni preziose.
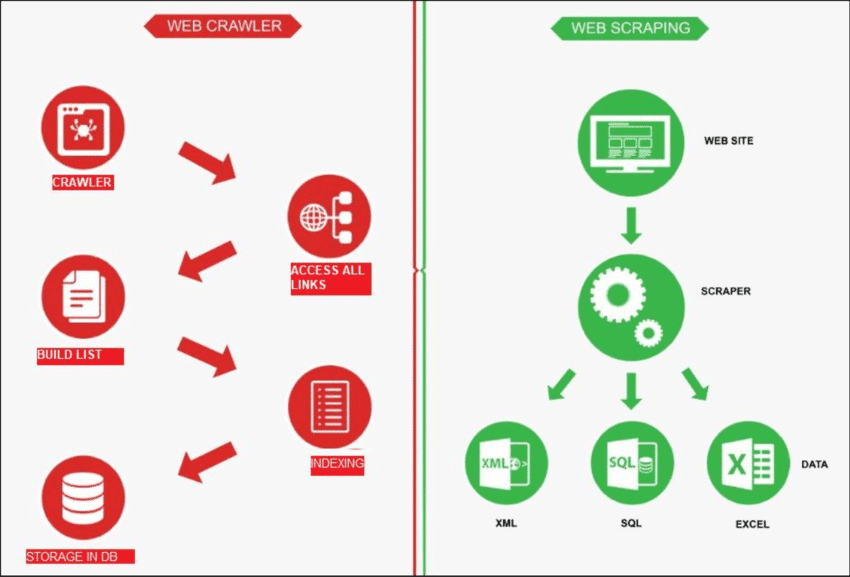
Fonte: RicercaGate
Scansione del Web
Il web crawling è come un robot che esplora Internet per trova nuove pagine. Il suo compito è fare un elenco di tutte le pagine là fuori. D'altro canto, il web scraping è come usare una lente di ingrandimento su siti specifici per ottenere dati da determinate pagine. Un web crawler, noto come spider, di solito inizia controllando alcuni URL principali di un sito particolare. Quindi segue i link ad altre pagine finché non ha trovato tutte le pagine che desidera.
Tuttavia, il web crawling ha diversi utilizzi, come la creazione di un elenco di pagine web e il monitoraggio delle modifiche apportate a un sito. Sia il web crawling che il web scraping sono importanti quando vogliamo acquisire informazioni dal web.
Web scraping
Il web scraping comporta estrazione di dati da un sito web di destinazione, solitamente fatto con strumenti automatizzati chiamati web scraper. Questi strumenti leggono il contenuto HTML di una pagina web per estrarre informazioni.
Ecco come funziona: lo scraper si collega prima alle pagine web pertinenti, che trova tramite un processo chiamato web crawling. Una volta lì, usa metodi come i selettori CSS per scegliere specifici Elementi HTML e raccogliere i dati necessari.
Web Crawling vs Web Scraping: una rapida occhiata
In parole povere, il web crawling riguarda la ricerca di link di siti web, mentre il web scraping riguarda la raccolta di dati da un sito web. In genere, la maggior parte dei progetti che implicano l'acquisizione di informazioni dal web richiedono sia il crawling che lo scraping.
| Caratteristica | Scansione del Web | Web scraping |
|---|---|---|
| Scopo | Indicizzazione e raccolta di informazioni dal web | Estrazione di dati specifici da siti web |
| Ambito | Indicizzazione e raccolta di informazioni dal web | Si concentra su pagine o contenuti specifici all'interno dei siti web |
| Profondità | In genere esplora l'intero sito web | Mira a dati specifici all'interno del sito web |
| Frequenza | Esegue regolarmente scansioni per aggiornare gli indici dei motori di ricerca | Estrazione dati occasionale o secondo necessità |
| Archiviazione dei dati | Memorizza metadati, link e indici di contenuto | Estrae e memorizza punti dati specifici |
| Tecniche | Segui i link per scoprire e indicizzare i contenuti | Utilizza l'analisi HTML per estrarre dati specifici |
| Esempi | Motori di ricerca che indicizzano le pagine web per i risultati di ricerca | Estrazione dei prezzi dei prodotti dai siti di e-commerce |
Ecco come funziona solitamente il web scraping:
✅ Scopri gli URL: Sfoglia un sito per trovare i link alle pagine web.
✅ Scarica HTML: Andate a quei link e salvate il codice del sito web (file HTML).
✅ Raccogli dati: Analizza i file HTML e seleziona i dati di cui hai bisogno.
Quindi, quando un sito web ha molte pagine, la scansione viene prima di tutto per trovarle prima di estrarre i dati. Ora, approfondiamo uno sguardo più dettagliato a web scraping vs web crawling.
Diversi casi d'uso di Web Crawling e Web Scraping
Web scraping e web crawling sono procedure separate che possono funzionare insieme in modo efficace. Possono anche essere utilizzate singolarmente, a seconda del lavoro da svolgere. Diamo un'occhiata ai molteplici casi d'uso di entrambi questi termini.

Risorsa: Raschiare l'eroe
Web Crawling: casi d'uso più comuni
Il Web crawling è utile per progetti che necessitano di una raccolta di link, che non hanno obiettivi specifici e che richiedono il recupero dell'intero codice di pagina senza ulteriore analisi. I casi di utilizzo comuni includono:
1. Indicizzazione dei motori di ricerca
- Google, Bing e Yahoo utilizzano i crawler per scoprire nuovi contenuti e pagine.
- I crawler memorizzano le informazioni in un indice, un vasto database a disposizione dell'utente.
2. Miglioramento delle prestazioni del sito
- Il web crawling aiuta ad analizzare e migliorare le prestazioni del tuo sito web.
- Rileva problemi come link non funzionanti, contenuti duplicati o problemi con i meta tag.
- Individua le opportunità per ottimizzare la struttura complessiva del sito.
3. Analisi del sito web della concorrenza
- Monitora i cambiamenti sia sul tuo sito web che su quello dei tuoi concorrenti per scopi SEO.
- Rimani informato sulle novità della concorrenza e reagisci tempestivamente.
4. Estrazione dei dati
- I web crawler raccolgono e analizzano grandi set di dati provenienti da diverse fonti online.
- Aiuta ricercatori, aziende e altri soggetti ad acquisire informazioni preziose.
5. Trovare link non funzionanti su siti esterni
- Controllare e aggiornare i link sui siti esterni per garantirne l'accuratezza.
- Utilizzare i crawler per gestire in modo efficiente la verifica dei link esterni.
6. Cura dei contenuti
- I crawler trovano in modo efficiente argomenti correlati ai contenuti per aziende o privati.
- Consente una rapida selezione in base a criteri specifici, come parole chiave o tag.
Web Scraping: casi d'uso più comuni
Al contrario, il web scraping è utile quando si ha un obiettivo di estrazione dati specifico. Viene comunemente applicato per:
1. Monitoraggio dei prezzi
- Consente il monitoraggio automatico dei prezzi dei prodotti sui siti di e-commerce.
- Facilita il rapido confronto dei prezzi su più piattaforme online.
- Consente alle aziende di rimanere informate in tempo reale sulle variazioni dei prezzi.
2. Aggregazione dei contenuti
- Consente l'aggregazione dei contenuti estraendo informazioni rilevanti da più fonti.
- Semplifica la raccolta di contenuti automatizzando la raccolta di dati da varie pagine web.
- Aiuta a consolidare contenuti diversi, rendendoli accessibili in un'unica posizione centralizzata.
3. Trovare indizi
- Identifica ed estrae le informazioni di contatto, semplificando il processo di generazione di lead.
- Automatizza la raccolta di potenziali clienti da varie fonti online.
- Recupero rapido di preziosi dati aziendali per identificare e contattare potenziali clienti.
5. Studiare i social media
- Estrae commenti e opinioni degli utenti per l'analisi del sentiment sui social media.
- Raccoglie dati su argomenti di tendenza e post popolari a fini di ricerca.
- Raccoglie metriche sul coinvolgimento degli utenti per comprendere l'impatto dei social media.
6. Gestire la reputazione online
- Monitora e raccogli le menzioni online per gestire e mantenere una reputazione online positiva.
- Estrarre e analizzare dati rilevanti che aiutano a risolvere potenziali problemi di reputazione.
- Tieni traccia del feedback dei clienti e rispondi per una gestione efficace della reputazione online.
Siate consapevoli delle sfide comuni del Web Crawling e del Web Scraping
Tuttavia, web crawling vs web scraping presenta alcuni ostacoli da affrontare. La complessità di queste sfide varia in base alle dimensioni del progetto, spaziando da ostacoli tecnici come tempi di caricamento lenti a considerazioni legali relative alle leggi sulla privacy dei dati.
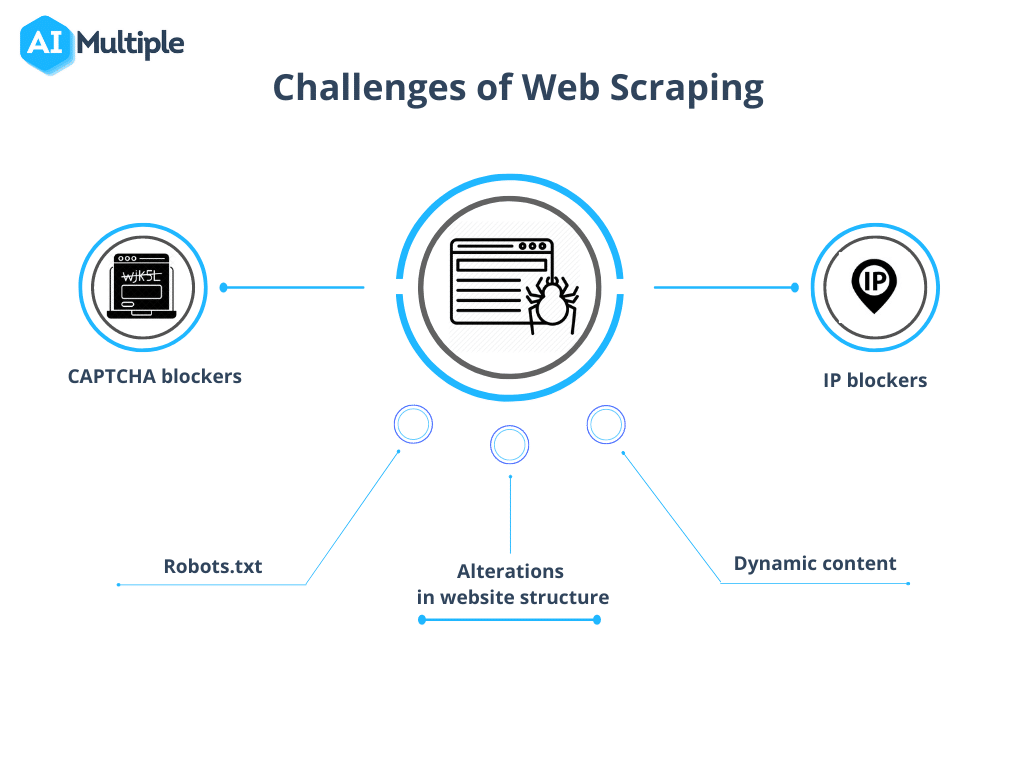
Fonte: AI Multipla
1. Robots.txt blocca le scansioni
Prima di iniziare una scansione, è fondamentale confermare le autorizzazioni del sito. Se il file robots.txt indica restrizioni sull'uso di dati da pagine specifiche, è opportuno rispettare tali termini.
2. Blocco IP
Durante la scansione, è essenziale evitare azioni che imitano troppo da vicino il comportamento umano, poiché ciò potrebbe portare a sospetti e al blocco dell'IP. Si consiglia di utilizzare un breve ritardo tra le richieste e di impiegare proxy per mascherare l'indirizzo IP reale. È anche consigliabile ruotare attraverso un pool di proxy.
3. Trappole per ragni
Alcune risorse impiegano trappole per crawler note come Honeypot. Questi link nascosti nel codice, invisibili agli utenti normali, possono portare un crawler al rilevamento e al successivo blocco.
4. CAPTCHA
Per ridurre al minimo gli incontri con CAPTCHA, attenersi alle linee guida fornite sopra. Quando i CAPTCHA sono inevitabili, prendere in considerazione l'utilizzo di servizi di risoluzione dei CAPTCHA.
5. Strisciare troppo
Una programmazione non corretta può causare il blocco di un bot in un loop infinito o un crawling eccessivo, con conseguente sovraccarico del sito Web di destinazione. Ciò può interrompere l'accesso di altri utenti che necessitano di risorse dal sito.
Conclusione: conoscere la differenza e agire di conseguenza
In parole povere, l'obiettivo del web scraping è raccogliere informazioni dalle pagine web, mentre il web crawling si concentra sull'indicizzazione e la localizzazione delle pagine web. Il web crawling comporta l'esplorazione continua dei link tramite hyperlink. D'altro canto, il web scraping comporta la creazione di un programma discreto in grado di raccogliere dati da vari siti web.
Allora, questo blog ti è stato utile? Condividi i tuoi pensieri, unisciti al nostro Comunità di Facebook per entrare in contatto con altri appassionati e iscriviti ai nostri blog per altri blog come questo.