ウェブクローリングとウェブスクレイピングの違いについて疑問に思ったことはありませんか?あなただけではありません。これらの用語はよく混同されますが、同じではありません。特にウェブサイトからデータを取得する場合は、違いを知ることが重要です。この記事では、 ウェブクローリングとウェブスクレイピング 詳細を説明します。さっそく始めましょう。

Web クロールと Web スクレイピングとは何ですか?
すべての検索クエリとデータが豊富な Web サイトの舞台裏には、Web クロールと Web スクレイピングを含む魅力的なプロセスが存在します。これら 2 つの不可欠なコンポーネントは連携して動作し、貴重な情報をナビゲートして抽出します。
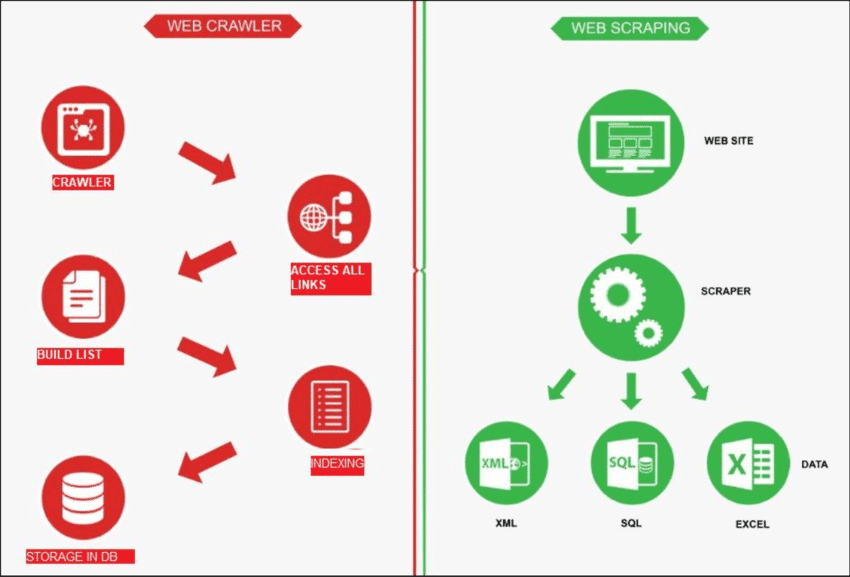
ソース: リサーチゲート
ウェブクローリング
ウェブクローリングはインターネットを探索するロボットのようなもので、 新しいページを見つけるその仕事は、そこにあるすべてのページのリストを作成することです。一方、ウェブスクレイピングは、特定のサイトに虫眼鏡をかけるようなものです。 特定のページからデータを取得するスパイダーと呼ばれる Web クローラーは、通常、特定のサイトの主要な URL をいくつかチェックすることから始めます。次に、必要なページがすべて見つかるまで、他のページへのリンクをたどります。
ただし、Web クロールには、Web ページのリストを作成したり、サイトの変更を監視したりするなど、さまざまな用途があります。Web から情報を取得する場合、Web クロールと Web スクレイピングはどちらも重要です。
ウェブスクレイピング
ウェブスクレイピングには 対象ウェブサイトからデータを取得する通常は、Web スクレイパーと呼ばれる自動化ツールで行われます。これらのツールは、Web ページの HTML コンテンツを読み取って情報を抽出します。
仕組みは次の通りです。まず、スクレイパーはウェブクローリングと呼ばれるプロセスを通じて関連するウェブページを見つけ、そこに接続します。そこで、CSSセレクタなどの方法を使用して特定のページを選択します。 HTML要素 必要なデータを収集します。
Web クローリングと Web スクレイピング: 簡単に比較
簡単に言えば、Web クローリングは Web サイトのリンクを見つけることであり、Web スクレイピングは Web サイトからデータを収集することです。通常、Web から情報を取得するほとんどのプロジェクトでは、クローリングとスクレイピングの両方が必要です。
| 特徴 | ウェブクローリング | ウェブスクレイピング |
|---|---|---|
| 目的 | ウェブからの情報のインデックス作成と収集 | ウェブサイトから特定のデータを抽出する |
| 範囲 | ウェブからの情報のインデックス作成と収集 | ウェブサイト内の特定のページやコンテンツに焦点を当てる |
| 深さ | 通常はウェブサイト全体を探索します | ウェブサイト内の特定のデータをターゲットとする |
| 頻度 | 定期的にクロールして検索エンジンのインデックスを更新します | 随時または必要に応じてデータ抽出 |
| データストレージ | メタデータ、リンク、コンテンツインデックスを保存します | 特定のデータポイントを抽出して保存する |
| テクニック | リンクをたどってコンテンツを発見し、インデックスを作成する | HTML解析を利用して特定のデータを抽出します |
| 例 | 検索エンジンが検索結果のためにウェブページをインデックスする | 電子商取引サイトから商品価格を抽出する |
Web スクレイピングは通常次のように機能します。
✅ URL を発見: サイトを調べて、Web ページのリンクを見つけます。
✅ HTML をダウンロード: それらのリンクにアクセスし、Web サイトのコード (HTML ファイル) を保存します。
✅ スクレイピングデータ: HTML ファイルを分析し、必要なデータを抽出します。
したがって、Web サイトに多数のページがある場合は、データをスクレイピングする前に、まずクロールしてページを見つけます。それでは、Web スクレイピングと Web クロールについてさらに詳しく見ていきましょう。
ウェブクロールとウェブスクレイピングのさまざまな使用例
Web スクレイピングと Web クロールは、効果的に連携できる別々の手順です。また、手元の作業に応じて個別に使用することもできます。これら 2 つの用語のさまざまな使用例を見てみましょう。

リソース: スクレイプヒーロー
ウェブクローリング: 最も一般的な使用例
Web クロールは、リンクの収集が必要で、特定のターゲットがなく、追加の解析なしでページ コード全体を取得する必要があるプロジェクトに役立ちます。一般的な使用例は次のとおりです。
1. 検索エンジンのインデックス
- Google、Bing、Yahoo はクローラーを使用して新しいコンテンツやページを検出します。
- クローラーは、ユーザーが検索するための巨大なデータベースであるインデックスに情報を保存します。
2. サイトパフォーマンスの向上
- Web クロールは、Web サイトのパフォーマンスの分析と強化に役立ちます。
- 壊れたリンク、重複コンテンツ、メタタグの問題などの問題を検出します。
- サイト全体の構造を最適化する機会を特定します。
3. 競合他社のウェブサイト分析
- SEO の目的で、自社と競合他社の Web サイトの両方の変更を監視します。
- 競合他社の最新情報を常に把握し、迅速に対応してください。
4. データマイニング
- Web クローラーは、さまざまなオンライン ソースから大量のデータ セットを収集して分析します。
- 研究者、企業、その他の人々が貴重な洞察を得ることを支援します。
5. 外部サイトのリンク切れを見つける
- 正確性を維持するために、外部サイト上のリンクを確認して更新します。
- クローラーを使用して外部リンクの検証を効率的に処理します。
6. コンテンツキュレーション
- クローラーは、企業や個人のコンテンツ関連のトピックを効率的に見つけます。
- キーワードやタグなどの特定の基準に基づいて、すばやくキュレーションを行うことができます。
ウェブスクレイピング: 最も一般的な使用例
対照的に、Web スクレイピングは、特定のデータ抽出目標がある場合に役立ちます。一般的には、次のような用途に使用されます。
1. 価格の追跡
- 電子商取引サイト上の製品価格の自動追跡を可能にします。
- 複数のオンライン プラットフォーム間で価格をすばやく比較できます。
- 企業が価格変更に関する情報をリアルタイムで把握できるようにします。
2. コンテンツの集約
- 複数のソースから関連情報を抽出することでコンテンツの集約を可能にします。
- さまざまな Web ページからのデータの収集を自動化することで、コンテンツの収集を効率化します。
- 多様なコンテンツを統合し、一元化された場所でアクセスできるようにします。
3. リードを見つける
- 連絡先情報を識別して抽出し、リード生成プロセスを合理化します。
- さまざまなオンライン ソースからの潜在的なリードの収集を自動化します。
- 貴重なビジネス データをすばやく取得して、潜在的な顧客を特定し、連絡を取ることができます。
5. ソーシャルメディアの勉強
- ソーシャル メディアの感情分析のためにユーザーのコメントと感情を抽出します。
- 調査目的でトレンドのトピックや人気の投稿に関するデータを収集します。
- ソーシャル メディアの影響を理解するために、ユーザー エンゲージメント メトリックを収集します。
6. オンライン評判の管理
- オンラインでの言及を監視および収集し、肯定的なオンラインでの評判を管理および維持します。
- 潜在的な評判の問題に対処するのに役立つ関連データを抽出して分析します。
- 効果的なオンライン評判管理のために、顧客からのフィードバックを追跡して対応します。
ウェブクローリングとウェブスクレイピングの一般的な課題に注意する
ただし、Web クローリングと Web スクレイピングには、対処すべき特定のハードルがあります。これらの課題の複雑さは、読み込み時間の遅さなどの技術的な障害から、データ プライバシー法に関連する法的考慮事項まで、プロジェクトの規模によって異なります。
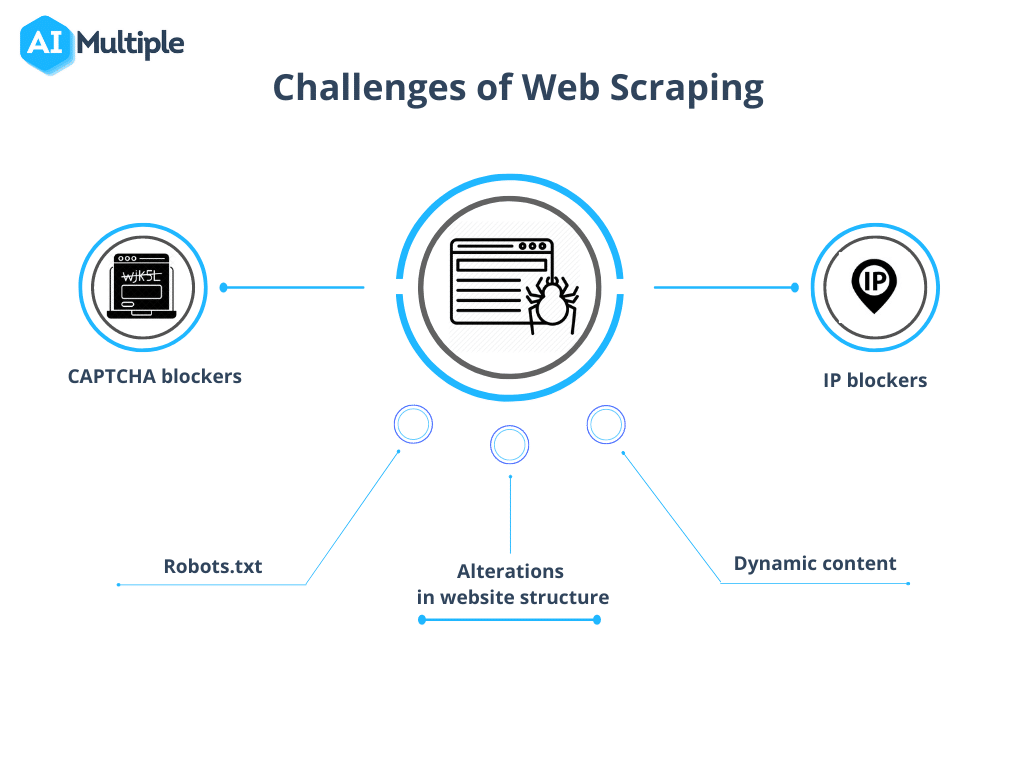
ソース: AI 複数
1. robots.txt によるクロールのブロック
クロールを開始する前に、サイトの権限を確認することが重要です。robots.txt ファイルに特定のページのデータの使用に関する制限が示されている場合は、これらの条件を尊重するのが賢明です。
2. IPブロッキング
クローリング中は、疑惑や IP ブロックにつながる可能性があるため、人間の行動を模倣しすぎるアクションを避けることが重要です。リクエスト間に短い遅延を設け、プロキシを使用して実際の IP アドレスを隠すことをお勧めします。プロキシのプールをローテーションすることもお勧めします。
3. クモトラップ
特定のリソースでは、ハニーポットと呼ばれるクローラー トラップが使用されています。コード内のこれらの隠しリンクは、一般ユーザーには見えず、クローラーによって検出され、ブロックされる可能性があります。
4. CAPTCHA
遭遇を最小限に抑えるために CAPTCHA について上記のガイドラインに従ってください。CAPTCHA が避けられない場合は、CAPTCHA 解決サービスを利用することを検討してください。
5. オーバークロール
不適切なプログラミングにより、ボットが無限ループに陥ったり、過度にクロールしたりして、対象の Web サイトに過度の負荷がかかる可能性があります。これにより、サイトのリソースを必要とする他のユーザーによるアクセスが妨げられる可能性があります。
結論:違いを理解し、それに応じて行動する
簡単に言えば、Web スクレイピングの目的は Web ページから情報を収集することであり、Web クロールは Web ページのインデックス作成と検索に重点を置いています。Web クロールでは、ハイパーリンクを介してリンクを継続的に探索します。一方、Web スクレイピングでは、さまざまな Web サイトからデータを収集できる個別のプログラムを作成します。
このブログはあなたにとって役に立ちましたか?ご意見をお寄せください。 Facebookコミュニティ 同じ趣味を持つ仲間と交流し、 ブログを購読する このようなブログをもっと見たい方は。