Heb je je ooit afgevraagd wat het verschil is tussen webcrawlen en webscraping? Je bent niet de enige. Deze termen worden vaak door elkaar gehaald, maar ze zijn niet hetzelfde. Het is belangrijk om het onderscheid te kennen, vooral als je data van websites haalt. In dit artikel zullen we webcrawlen versus webscraping in detail. Laten we er zonder verder oponthoud induiken.

Wat is webcrawling en webscraping?
Achter de schermen van elke zoekopdracht en datarijke website schuilt een fascinerend proces dat webcrawlen en webscraping omvat. Deze twee integrale componenten werken hand in hand om waardevolle informatie te navigeren en te extraheren.
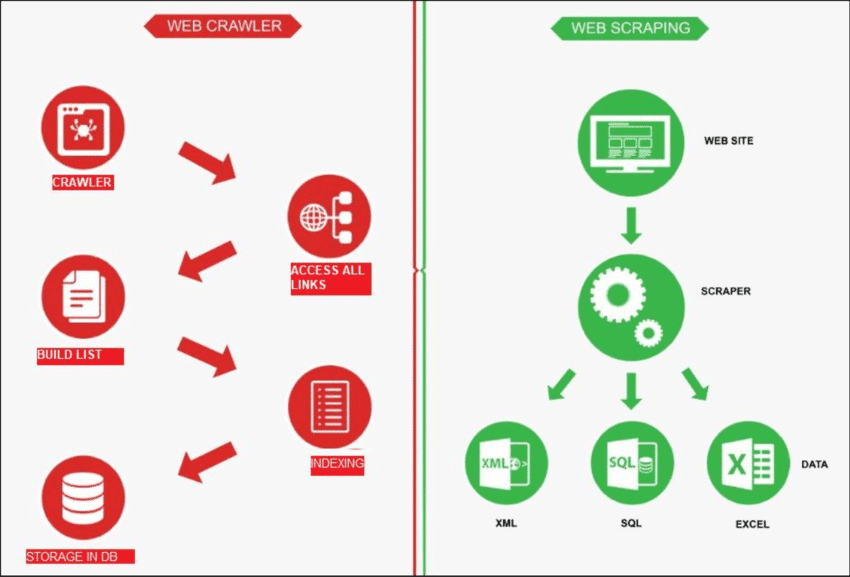
Bron: Onderzoekspoort
Webcrawlen
Webcrawling is als een robot die het internet verkent om vind nieuwe pagina's. De taak is om een lijst te maken van alle pagina's die er zijn. Aan de andere kant is web scraping als het gebruiken van een vergrootglas op specifieke sites om gegevens ophalen van bepaalde pagina's. Een webcrawler, ook wel spider genoemd, begint meestal met het controleren van een paar hoofd-URL's van een bepaalde site. Vervolgens volgt hij links naar andere pagina's totdat hij alle gewenste pagina's heeft gevonden.
Webcrawlen heeft echter andere toepassingen, zoals het maken van een lijst met webpagina's en het in de gaten houden van wijzigingen aan een site. Zowel webcrawlen als webscraping zijn belangrijk als we informatie van het web willen halen.
Webscraping
Webscraping omvat gegevens ophalen van een doelwebsite, meestal gedaan met geautomatiseerde tools genaamd web scrapers. Deze tools lezen de HTML-inhoud van een webpagina om informatie te extraheren.
Zo werkt het: de scraper maakt eerst verbinding met de relevante webpagina's, die hij vindt via een proces dat webcrawlen heet. Eenmaal daar gebruikt hij methoden zoals CSS-selectors om specifieke HTML-elementen en de benodigde gegevens verzamelen.
Webcrawling versus webscraping: een snelle blik
Simpel gezegd gaat webcrawlen over het vinden van websitelinks, en webscraping gaat over het verzamelen van gegevens van een website. Meestal vereisen de meeste projecten waarbij informatie van het web wordt gehaald zowel crawlen als scrapen.
| Functie | Webcrawlen | Webscraping |
|---|---|---|
| Doel | Indexeren en verzamelen van informatie van het web | Specifieke gegevens uit websites halen |
| Domein | Indexeren en verzamelen van informatie van het web | Richt zich op specifieke pagina's of inhoud binnen websites |
| Diepte | Verkent doorgaans de hele website | Richt zich op specifieke gegevens binnen de website |
| Frequentie | Crawlt regelmatig om zoekmachine-indexen bij te werken | Incidentele of indien nodig gegevensextractie |
| Gegevensopslag | Slaat metagegevens, links en inhoudsindexen op | Extraheert en slaat specifieke datapunten op |
| Technieken | Volgt links om inhoud te ontdekken en te indexeren | Maakt gebruik van HTML-parsing om specifieke gegevens te extraheren |
| Voorbeelden | Zoekmachines indexeren webpagina's voor zoekresultaten | Productprijzen ophalen van e-commercesites |
Dit is hoe webscraping meestal werkt:
✅ Ontdek URL's: Zoek op een site naar de links naar de webpagina's.
✅ HTML downloaden: Ga naar deze links en sla de code van de website op (HTML-bestanden).
✅ Gegevens schrapen: Analyseer de HTML-bestanden en selecteer de gegevens die u nodig hebt.
Dus als een website veel pagina's heeft, is crawlen de eerste stap om ze te vinden voordat de data wordt gescraped. Laten we nu eens dieper ingaan op webscraping versus webcrawlen.
Verschillende toepassingsgevallen van webcrawling en webscraping
Web scraping en web crawling zijn aparte procedures die effectief samen kunnen werken. Ze kunnen ook afzonderlijk worden gebruikt, afhankelijk van de taak die voorhanden is. Laten we eens kijken naar de verschillende use cases van beide termen.

Bron: Schraapheld
Webcrawling: meest voorkomende gebruiksgevallen
Webcrawling is handig voor projecten die linkverzameling nodig hebben, specifieke doelen missen en het ophalen van de volledige paginacode vereisen zonder extra parsing. Veelvoorkomende use cases zijn:
1. Indexering door zoekmachines
- Google, Bing en Yahoo gebruiken crawlers om nieuwe content en pagina's te ontdekken.
- Crawlers slaan informatie op in een index, een enorme database die gebruikers kunnen raadplegen.
2. Verbetering van de siteprestaties
- Webcrawling helpt bij het analyseren en verbeteren van de prestaties van uw website.
- Problemen detecteren zoals kapotte links, dubbele inhoud of problemen met metatags.
- Identificeert mogelijkheden om de algehele sitestructuur te optimaliseren.
3. Analyse van de website van de concurrent
- Houd wijzigingen op uw eigen website en die van uw concurrenten bij voor SEO-doeleinden.
- Blijf op de hoogte van de updates van concurrenten en reageer snel.
4. Datamining
- Webcrawlers verzamelen en analyseren grote hoeveelheden data uit verschillende online bronnen.
- Helpt onderzoekers, bedrijven en anderen waardevolle inzichten te verkrijgen.
5. Gebroken links op externe sites vinden
- Controleer en update links op externe sites om ervoor te zorgen dat de informatie nauwkeurig is.
- Gebruik crawlers om externe linkverificatie efficiënt af te handelen.
6. Curatie van inhoud
- Crawlers vinden efficiënt contentgerelateerde onderwerpen voor bedrijven of individuen.
- Maakt snelle selectie mogelijk op basis van specifieke criteria, zoals trefwoorden of tags.
Webscraping: meest voorkomende use cases
Daarentegen is web scraping nuttig wanneer u een specifiek doel voor data-extractie heeft. Het wordt vaak toegepast voor:
1. Prijzen volgen
- Maakt het mogelijk om productprijzen op e-commercesites automatisch te volgen.
- Maakt het mogelijk om snel prijzen op meerdere online platforms te vergelijken.
- Zorgt ervoor dat bedrijven in realtime op de hoogte blijven van prijswijzigingen.
2. Inhoud aggregeren
- Maakt het mogelijk om inhoud te aggregeren door relevante informatie uit meerdere bronnen te halen.
- Stroomlijnt het verzamelen van content door het verzamelen van gegevens van verschillende webpagina's te automatiseren.
- Helpt bij het consolideren van diverse content, zodat deze op een centrale locatie toegankelijk is.
3. Leads vinden
- Identificeert en extraheert contactgegevens, waardoor het leadgeneratieproces wordt gestroomlijnd.
- Automatiseert het verzamelen van potentiële leads uit verschillende online bronnen.
- Snel waardevolle bedrijfsgegevens ophalen om potentiële klanten te identificeren en contact met hen op te nemen.
5. Sociale media bestuderen
- Haalt gebruikerscommentaren en -sentiment op voor sentimentanalyse op sociale media.
- Verzamelt gegevens over trending topics en populaire berichten voor onderzoeksdoeleinden.
- Verzamelt gegevens over gebruikersbetrokkenheid om inzicht te krijgen in de impact van sociale media.
6. Online reputatie beheren
- Houd toezicht op en verzamel online vermeldingen om een positieve online reputatie te beheren en te behouden.
- Haal relevante gegevens op en analyseer deze, zodat u potentiële reputatieproblemen kunt aanpakken.
- Houd feedback van klanten bij en reageer erop voor effectief online reputatiebeheer.
Wees u bewust van veelvoorkomende uitdagingen bij webcrawling en webscraping
Niettemin heeft webcrawlen versus webscraping bepaalde obstakels om mee om te gaan. De complexiteit van deze uitdagingen varieert afhankelijk van de grootte van het project, variërend van technische obstakels zoals trage laadtijden tot juridische overwegingen met betrekking tot wetten inzake gegevensprivacy.
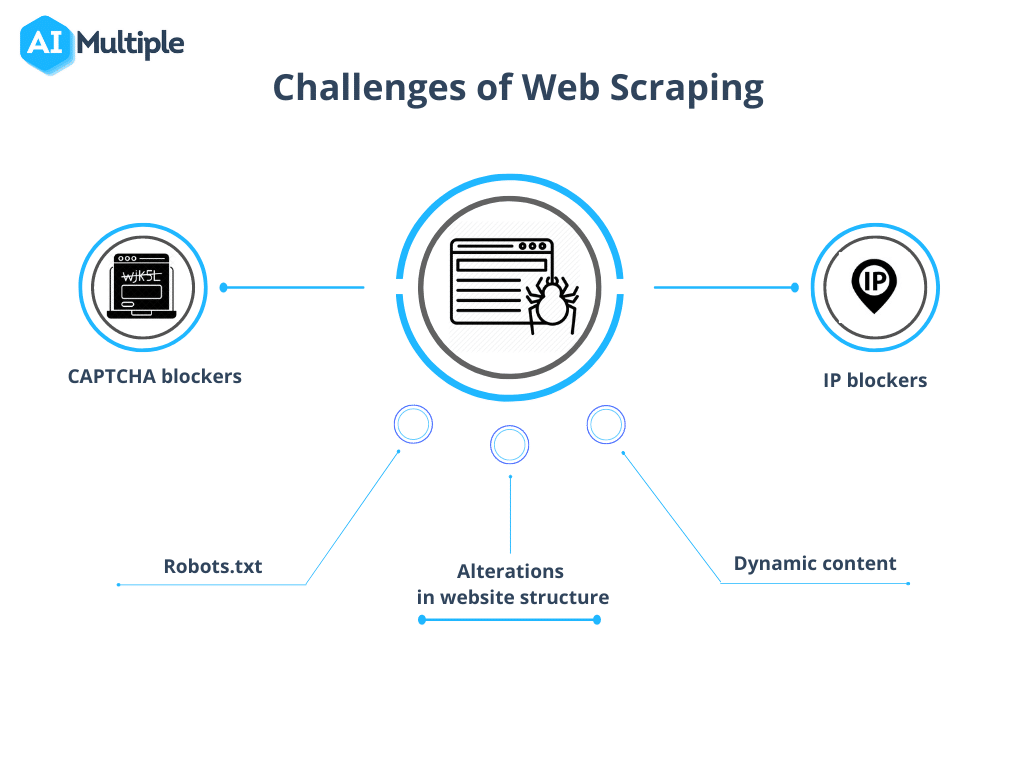
Bron: AI Meervoudig
1. Robots.txt blokkeert crawls
Voordat u een crawl start, is het cruciaal om de permissies van de site te bevestigen. Als het robots.txt-bestand beperkingen aangeeft voor het gebruik van data van specifieke pagina's, is het verstandig om deze voorwaarden te respecteren.
2. IP-blokkering
Tijdens het crawlen is het essentieel om acties te vermijden die te veel lijken op menselijk gedrag, omdat dit kan leiden tot verdenking en IP-blokkering. Het is aan te raden om een korte vertraging tussen verzoeken te gebruiken en proxy's te gebruiken om het echte IP-adres te maskeren. Het is ook raadzaam om te roteren door een pool van proxy's.
3. Spinnenvallen
Bepaalde bronnen gebruiken crawler traps, bekend als Honeypots. Deze verborgen links in de code, onzichtbaar voor gewone gebruikers, kunnen een crawler naar detectie en daaropvolgende blokkering leiden.
4. CAPTCHA's
Om ontmoetingen met CAPTCHA's, houd u aan de bovenstaande richtlijnen. Wanneer CAPTCHA's onvermijdelijk zijn, overweeg dan om CAPTCHA-oplossingsservices te gebruiken.
5. Te veel kruipen
Onjuiste programmering kan ertoe leiden dat een bot vast komt te zitten in een eindeloze lus of overmatig crawlt, waardoor de doelwebsite onnodig wordt belast. Dit kan de toegang verstoren voor andere gebruikers die bronnen van de site nodig hebben.
Kortom: ken het verschil en werk dienovereenkomstig
Simpel gezegd is het doel van web scraping om informatie van webpagina's te verzamelen, terwijl web crawling gericht is op het indexeren en lokaliseren van webpagina's. Web crawling omvat het continu verkennen van links via hyperlinks. Aan de andere kant omvat web scraping het creëren van een discreet programma dat in staat is om gegevens van verschillende websites te verzamelen.
Dus, was deze blog nuttig voor u? Deel uw gedachten, word lid van onze Facebook-gemeenschap om in contact te komen met andere enthousiastelingen, en abonneer je op onze blogs voor meer blogs zoals deze.