Czy kiedykolwiek zastanawiałeś się nad różnicą między web crawlingiem a web scrapingiem? Nie jesteś sam. Te terminy są często mylone, ale nie są takie same. Znajomość rozróżnienia jest kluczowa, zwłaszcza jeśli chcesz pobierać dane ze stron internetowych. W tym artykule omówimy indeksowanie sieci a scrapowanie sieci szczegółowo. Bez zbędnych ceregieli, przejdźmy do konkretów.

Czym jest Web Crawling i Web Scraping?
Za kulisami każdego zapytania wyszukiwania i bogatej w dane witryny kryje się fascynujący proces, który obejmuje indeksowanie sieci i skrobanie sieci. Te dwa integralne komponenty współpracują ze sobą, aby nawigować i wydobywać cenne informacje.
Źródło: Brama badawcza
Przeszukiwanie sieci
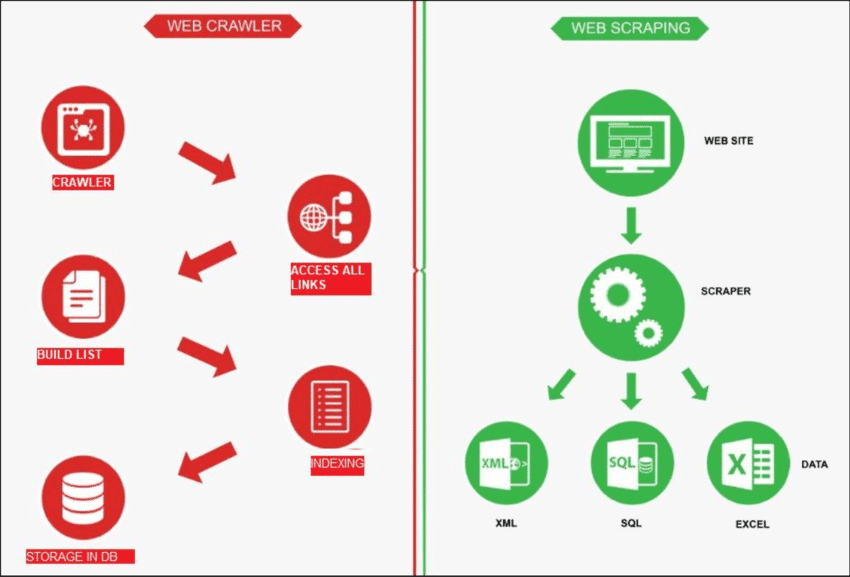
Przeszukiwanie sieci to proces, w którym robot eksploruje Internet w celu znajdź nowe strony. Jego zadaniem jest utworzenie listy wszystkich dostępnych stron. Z drugiej strony, web scraping jest jak używanie lupy na określonych stronach, aby pobierz dane z określonych stron. Robot sieciowy, znany jako pająk, zwykle zaczyna od sprawdzenia kilku głównych adresów URL konkretnej witryny. Następnie podąża za linkami do innych stron, aż znajdzie wszystkie strony, których potrzebuje.
Jednakże web crawling ma różne zastosowania, takie jak tworzenie listy stron internetowych i śledzenie zmian na stronie. Zarówno web crawling, jak i web scraping są ważne, gdy chcemy pobrać informacje z sieci.
Scraping sieciowy
Scraping sieciowy obejmuje pobieranie danych z docelowej witryny internetowej, zwykle wykonywane za pomocą zautomatyzowanych narzędzi zwanych web scraperami. Te narzędzia odczytują zawartość HTML strony internetowej w celu wyodrębnienia informacji.
Oto jak to działa: scraper najpierw łączy się z odpowiednimi stronami internetowymi, które znajduje za pomocą procesu zwanego web crawlingiem. Po dotarciu tam używa metod, takich jak selektory CSS, aby wybrać określone Elementy HTML i zebrać potrzebne dane.
Przeszukiwanie sieci a skrobanie sieci: szybki przegląd
Mówiąc prościej, web crawling polega na znajdowaniu linków do stron internetowych, a web scraping polega na zbieraniu danych ze strony internetowej. Zazwyczaj większość projektów obejmujących pobieranie informacji z sieci wymaga zarówno crawlowania, jak i scrapowania.
| Funkcja | Przeszukiwanie sieci | Scraping sieciowy |
|---|---|---|
| Zamiar | Indeksowanie i gromadzenie informacji z sieci | Wyodrębnianie określonych danych ze stron internetowych |
| Zakres | Indeksowanie i gromadzenie informacji z sieci | Koncentruje się na określonych stronach lub treściach w witrynach internetowych |
| Głębokość | Zwykle przegląda całą witrynę | Celuje w określone dane w obrębie witryny |
| Częstotliwość | Regularnie indeksuje w celu aktualizacji indeksów wyszukiwarek | Okazjonalne lub doraźne pobieranie danych |
| Przechowywanie danych | Przechowuje metadane, linki i indeksy treści | Ekstrahuje i przechowuje określone punkty danych |
| Techniki | Podąża za linkami, aby odkrywać i indeksować treści | Wykorzystuje analizę składniową HTML do wyodrębniania określonych danych |
| Przykłady | Wyszukiwarki indeksujące strony internetowe w celu uzyskania wyników wyszukiwania | Ekstrakcja cen produktów ze stron e-commerce |
Oto jak zazwyczaj działa scrapowanie sieci:
✅ Odkryj adresy URL: Przejrzyj witrynę, aby znaleźć linki do stron internetowych.
✅ Pobierz HTML: Kliknij te linki i zapisz kod witryny (pliki HTML).
✅ Zbieranie danych: Przeanalizuj pliki HTML i wybierz potrzebne Ci dane.
Więc kiedy strona internetowa ma wiele stron, najpierw następuje indeksowanie, aby je znaleźć, zanim zeskrobiemy dane. Teraz zagłębmy się w bardziej szczegółowe spojrzenie na web scraping vs web crawling.
Różne przypadki użycia indeksowania sieci i skrobania sieci
Web scraping i web crawling to oddzielne procedury, które mogą skutecznie ze sobą współpracować. Mogą być również używane indywidualnie, w zależności od wykonywanego zadania. Przyjrzyjmy się licznym przypadkom użycia obu tych terminów.

Ratunek: Bohater Scrape'a
Przeszukiwanie sieci: najczęstsze przypadki użycia
Web crawling jest przydatny w przypadku projektów wymagających zbierania linków, braku określonych celów i wymagających pobrania całego kodu strony bez dodatkowego parsowania. Typowe przypadki użycia obejmują:
1. Indeksowanie przez wyszukiwarki
- Google, Bing i Yahoo używają robotów indeksujących do odkrywania nowych treści i stron.
- Roboty indeksujące przechowują informacje w indeksie, ogromnej bazie danych umożliwiającej użytkownikom pobieranie informacji.
2. Poprawa wydajności witryny
- Przeszukiwanie sieci pomaga w analizie i zwiększaniu wydajności Twojej witryny.
- Wykrywaj problemy, takie jak uszkodzone linki, zduplikowaną treść lub problemy z meta tagami.
- Identyfikuje możliwości optymalizacji ogólnej struktury witryny.
3. Analiza stron internetowych konkurencji
- Monitoruj zmiany na swojej stronie internetowej i stronach konkurencji pod kątem SEO.
- Bądź na bieżąco z aktualizacjami konkurencji i reaguj na bieżąco.
4. Eksploracja danych
- Roboty sieciowe zbierają i analizują duże zbiory danych z różnych źródeł internetowych.
- Ułatwia badaczom, przedsiębiorcom i innym osobom zdobywanie cennych informacji.
5. Znajdowanie uszkodzonych linków na stronach zewnętrznych
- Sprawdzaj i aktualizuj linki na stronach zewnętrznych, aby zachować dokładność.
- Użyj crawlerów, aby skutecznie obsługiwać weryfikację linków zewnętrznych.
6. Kultura treści
- Roboty indeksujące skutecznie wyszukują treści powiązane z firmami i osobami prywatnymi.
- Umożliwia szybką selekcję na podstawie określonych kryteriów, takich jak słowa kluczowe lub tagi.
Web Scraping: Najczęstsze przypadki użycia
Natomiast web scraping jest przydatny, gdy masz konkretny cel ekstrakcji danych. Jest powszechnie stosowany do:
1. Śledzenie cen
- Umożliwia automatyczne śledzenie cen produktów na stronach e-commerce.
- Umożliwia szybkie porównywanie cen na wielu platformach internetowych.
- Umożliwia przedsiębiorstwom śledzenie zmian cen w czasie rzeczywistym.
2. Agregowanie treści
- Umożliwia agregację treści poprzez wyodrębnianie istotnych informacji z wielu źródeł.
- Usprawnia gromadzenie treści poprzez automatyzację gromadzenia danych z różnych stron internetowych.
- Pomaga w konsolidacji różnorodnych treści, udostępniając je w jednym miejscu.
3. Znajdowanie leadów
- Identyfikuje i wyodrębnia dane kontaktowe, usprawniając proces pozyskiwania potencjalnych klientów.
- Automatyzuje zbieranie potencjalnych klientów z różnych źródeł internetowych.
- Szybkie wyszukiwanie cennych danych biznesowych w celu identyfikacji i nawiązania kontaktu z potencjalnymi klientami.
5. Badanie mediów społecznościowych
- Wyodrębnia komentarze i opinie użytkowników na potrzeby analizy nastrojów w mediach społecznościowych.
- Gromadzi dane na temat popularnych tematów i postów w celach badawczych.
- Gromadzi dane dotyczące zaangażowania użytkowników w celu zrozumienia wpływu mediów społecznościowych.
6. Zarządzanie reputacją online
- Monitoruj i zbieraj wzmianki online, aby zarządzać i utrzymywać pozytywną reputację online.
- Wyodrębnij i przeanalizuj istotne dane, które pomogą rozwiązać potencjalne problemy związane z reputacją.
- Śledź opinie klientów i reaguj na nie, aby skutecznie zarządzać reputacją online.
Bądź świadomy typowych wyzwań związanych z indeksowaniem sieci i scrapowaniem sieci
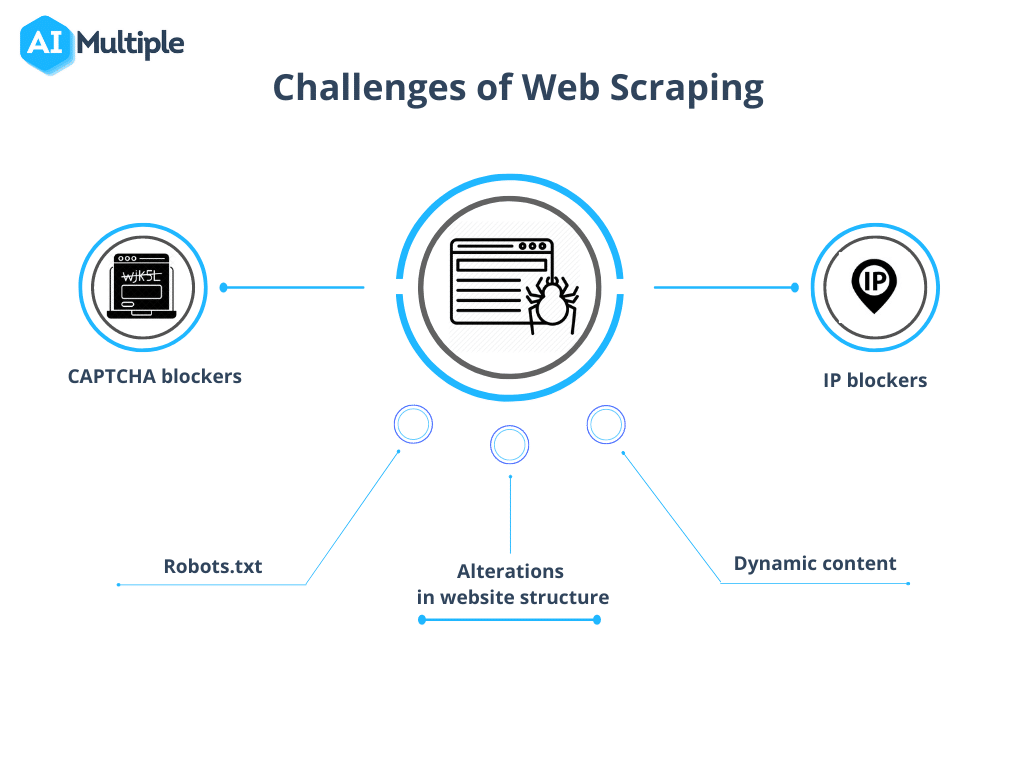
Niemniej jednak web crawling kontra web scraping ma pewne przeszkody do pokonania. Złożoność tych wyzwań różni się w zależności od rozmiaru projektu, od przeszkód technicznych, takich jak powolne czasy ładowania, po kwestie prawne związane z przepisami o ochronie danych.
Źródło: Wielokrotna sztuczna inteligencja
1. Robots.txt blokuje indeksowanie
Przed rozpoczęciem indeksowania konieczne jest potwierdzenie uprawnień witryny. Jeśli plik robots.txt wskazuje ograniczenia dotyczące korzystania z danych z określonych stron, rozsądnie jest przestrzegać tych warunków.
2. Blokowanie IP
Podczas indeksowania należy unikać działań, które zbyt ściśle naśladują ludzkie zachowanie, ponieważ może to prowadzić do podejrzeń i blokowania adresów IP. Zaleca się stosowanie krótkiego opóźnienia między żądaniami i używanie serwerów proxy w celu zamaskowania prawdziwego adresu IP. Zalecane jest również rotowanie w puli serwerów proxy.
3. Pułapki na pająki
Niektóre zasoby wykorzystują pułapki dla robotów indeksujących znane jako Honeypots. Te ukryte linki w kodzie, niewidoczne dla zwykłych użytkowników, mogą doprowadzić robota indeksującego do wykrycia i późniejszego zablokowania.
4. CAPTCHA
Aby zminimalizować liczbę spotkań z CAPTCHA, stosuj się do wytycznych podanych powyżej. Gdy CAPTCHA są nieuniknione, rozważ skorzystanie z usług rozwiązywania CAPTCHA.
5. Nadmierne pełzanie
Nieprawidłowe programowanie może spowodować, że bot utknie w nieskończonej pętli lub będzie nadmiernie indeksował, co spowoduje nadmierne obciążenie docelowej witryny. Może to zakłócić dostęp dla innych użytkowników potrzebujących zasobów z witryny.
Podsumowanie: Poznaj różnice i działaj zgodnie z nimi
Mówiąc prościej, celem web scrapingu jest zbieranie informacji ze stron internetowych, podczas gdy web crawling koncentruje się na indeksowaniu i lokalizowaniu stron internetowych. Web crawling obejmuje ciągłą eksplorację linków za pomocą hiperłączy. Z drugiej strony web scraping obejmuje tworzenie dyskretnego programu zdolnego do zbierania danych z różnych stron internetowych.
Czy ten blog był dla Ciebie pomocny? Podziel się swoimi przemyśleniami, dołącz do nas Społeczność na Facebooku aby nawiązać kontakt z innymi pasjonatami, i zapisz się na nasze blogi Więcej takich blogów znajdziesz tutaj.