Já se perguntou qual a diferença entre web crawling e web scraping? Você não está sozinho. Esses termos são frequentemente confundidos, mas não são a mesma coisa. Conhecer a distinção é fundamental, principalmente se você trabalha com extração de dados de sites. Neste artigo, vamos explicar a diferença. rastreamento da web vs. extração de dados da web Em detalhes. Sem mais delongas, vamos começar.

O que são Web Crawling e Web Scraping?
Por trás de cada pesquisa e site rico em dados, existe um processo fascinante que envolve rastreamento e extração de dados da web. Esses dois componentes essenciais trabalham em conjunto para navegar e extrair informações valiosas.
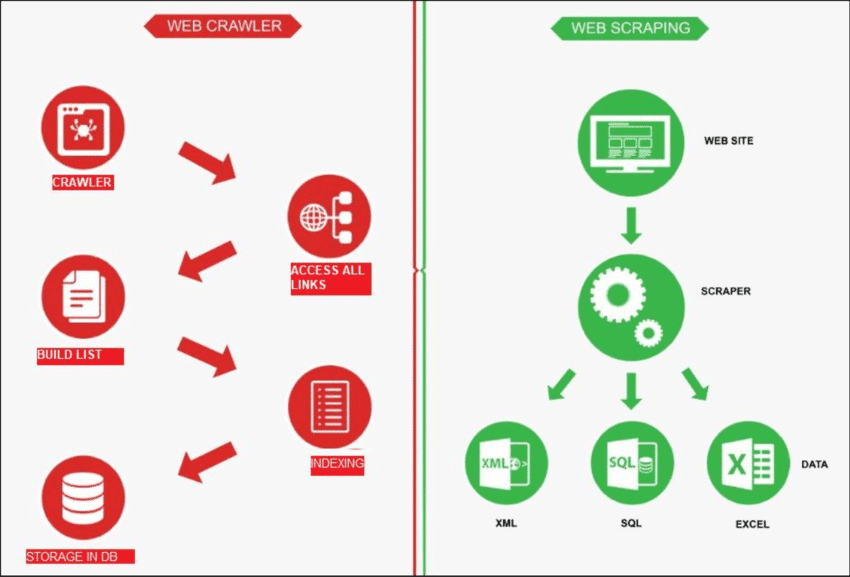
Fonte: ResearchGate
Rastreamento da Web
A coleta de dados na web é como um robô explorando a internet para encontrar novas páginas. Sua função é criar uma lista de todas as páginas existentes. Por outro lado, a extração de dados da web (web scraping) é como usar uma lupa em sites específicos para... obter dados de determinadas páginas. Um rastreador web, conhecido como spider, geralmente começa verificando alguns URLs principais de um determinado site. Em seguida, ele segue os links para outras páginas até encontrar todas as páginas desejadas.
No entanto, a coleta de dados da web (web crawling) tem usos diferentes, como criar listas de páginas da web e monitorar alterações em um site. Tanto a coleta de dados da web quanto a extração de dados da web são importantes quando queremos obter informações da internet.
Extração de dados da web
A extração de dados da web envolve Extraindo dados de um site de destino, geralmente feito com ferramentas automatizadas chamadas web scrapers. Essas ferramentas leem o conteúdo HTML de uma página da web para extrair informações.
Funciona assim: o scraper primeiro se conecta às páginas da web relevantes, que encontra por meio de um processo chamado web crawling. Uma vez lá, ele usa métodos como seletores CSS para escolher páginas específicas. Elementos HTML e reunir os dados necessários.
Web Crawling vs Web Scraping: Uma Visão Geral
Em termos simples, o web crawling consiste em encontrar links de sites, enquanto o web scraping consiste em coletar dados de um site. Normalmente, a maioria dos projetos que envolvem a obtenção de informações da web requer tanto o crawling quanto o scraping.
| Recurso | Rastreamento da Web | Extração de dados da web |
|---|---|---|
| Propósito | Indexação e coleta de informações da web | Extraindo dados específicos de sites |
| Escopo | Indexação e coleta de informações da web | Concentra-se em páginas ou conteúdo específicos dentro de sites. |
| Profundidade | Normalmente explora todo o site. | Identifica dados específicos dentro do site. |
| Freqüência | Realiza buscas regularmente para atualizar os índices dos mecanismos de busca. | Extração de dados ocasional ou conforme necessário |
| Armazenamento de dados | Armazena metadados, links e índices de conteúdo. | Extrai e armazena pontos de dados específicos. |
| Técnicas | Segue links para descobrir e indexar conteúdo. | Utiliza análise HTML para extrair dados específicos. |
| Exemplos | Mecanismos de busca indexam páginas da web para resultados de pesquisa | Extraindo preços de produtos de sites de comércio eletrônico |
Eis como geralmente funciona a extração de dados da web:
✅ Descubra URLs: Procure em um site os links para as páginas da web.
✅ Baixar HTML: Acesse esses links e salve o código do site (arquivos HTML).
✅ Extrair dados: Analise os arquivos HTML e selecione os dados de que precisa.
Portanto, quando um site tem muitas páginas, o rastreamento (crawling) é a primeira etapa para encontrá-las antes da extração dos dados (scraping). Agora, vamos analisar com mais detalhes a diferença entre web scraping e web crawling.
Diferentes casos de uso de rastreamento e extração de dados da web
Web scraping e web crawling são procedimentos distintos que podem funcionar em conjunto de forma eficaz. Também podem ser usados individualmente, dependendo da tarefa em questão. Vamos analisar os diversos casos de uso de ambos os termos.

Recurso: ScrapeHero
Rastreamento da Web: Casos de Uso Mais Comuns
A coleta de links na web é útil para projetos que precisam coletar links, não possuem alvos específicos e requerem a recuperação do código completo da página sem análise adicional. Casos de uso comuns incluem:
1. Indexação de mecanismos de busca
- O Google, o Bing e o Yahoo usam rastreadores para descobrir novos conteúdos e páginas.
- Os rastreadores armazenam informações em um índice, um vasto banco de dados para recuperação de dados pelo usuário.
2. Melhorando o desempenho do site
- A indexação da web auxilia na análise e melhoria do desempenho do seu site.
- Detecte problemas como links quebrados, conteúdo duplicado ou problemas com meta tags.
- Identifica oportunidades para otimizar a estrutura geral do site.
3. Análise do site da concorrência
- Monitore as alterações nos sites da sua empresa e dos seus concorrentes para fins de SEO.
- Mantenha-se informado sobre as atualizações dos concorrentes e reaja prontamente.
4. Mineração de Dados
- Os rastreadores da web coletam e analisam grandes conjuntos de dados de diversas fontes online.
- Facilita a obtenção de informações valiosas por pesquisadores, empresas ou outros.
5. Encontrando links quebrados em sites externos
- Verifique e atualize os links em sites externos para manter a precisão das informações.
- Utilize rastreadores para lidar de forma eficiente com a verificação de links externos.
6. Curadoria de Conteúdo
- Os rastreadores encontram, de forma eficiente, tópicos relacionados a conteúdo para empresas ou indivíduos.
- Permite uma curadoria rápida com base em critérios específicos, como palavras-chave ou tags.
Web Scraping: Casos de Uso Mais Comuns
Em contrapartida, a extração de dados da web (web scraping) é útil quando se tem um objetivo específico de extração de dados. É comumente aplicada para:
1. Acompanhamento de preços
- Permite o rastreamento automatizado dos preços dos produtos em sites de comércio eletrônico.
- Facilita a comparação rápida de preços em diversas plataformas online.
- Permite que as empresas se mantenham informadas sobre as mudanças de preços em tempo real.
2. Agregação de Conteúdo
- Permite a agregação de conteúdo através da extração de informações relevantes de múltiplas fontes.
- Simplifica a coleta de conteúdo automatizando a obtenção de dados de diversas páginas da web.
- Auxilia na consolidação de conteúdo diverso, tornando-o acessível em um local centralizado.
3. Encontrando leads
- Identifica e extrai informações de contato, otimizando o processo de geração de leads.
- Automatiza a coleta de potenciais clientes de diversas fontes online.
- Recuperação rápida de dados comerciais valiosos para identificar e entrar em contato com clientes potenciais.
5. Estudando as mídias sociais
- Extrai comentários e sentimentos de usuários para análise de sentimento em mídias sociais.
- Coleta dados sobre tópicos em alta e publicações populares para fins de pesquisa.
- Coleta métricas de engajamento do usuário para entender o impacto das mídias sociais.
6. Gerenciando a Reputação Online
- Monitore e colete menções online para gerenciar e manter uma reputação online positiva.
- Extrair e analisar dados relevantes que ajudem a solucionar potenciais problemas de reputação.
- Monitore e responda ao feedback dos clientes para uma gestão eficaz da reputação online.
Esteja ciente dos desafios comuns da coleta e extração de dados da web.
No entanto, a comparação entre web crawling e web scraping apresenta certos obstáculos. A complexidade desses desafios varia de acordo com o tamanho do projeto, desde obstáculos técnicos, como tempos de carregamento lentos, até considerações legais relacionadas às leis de privacidade de dados.
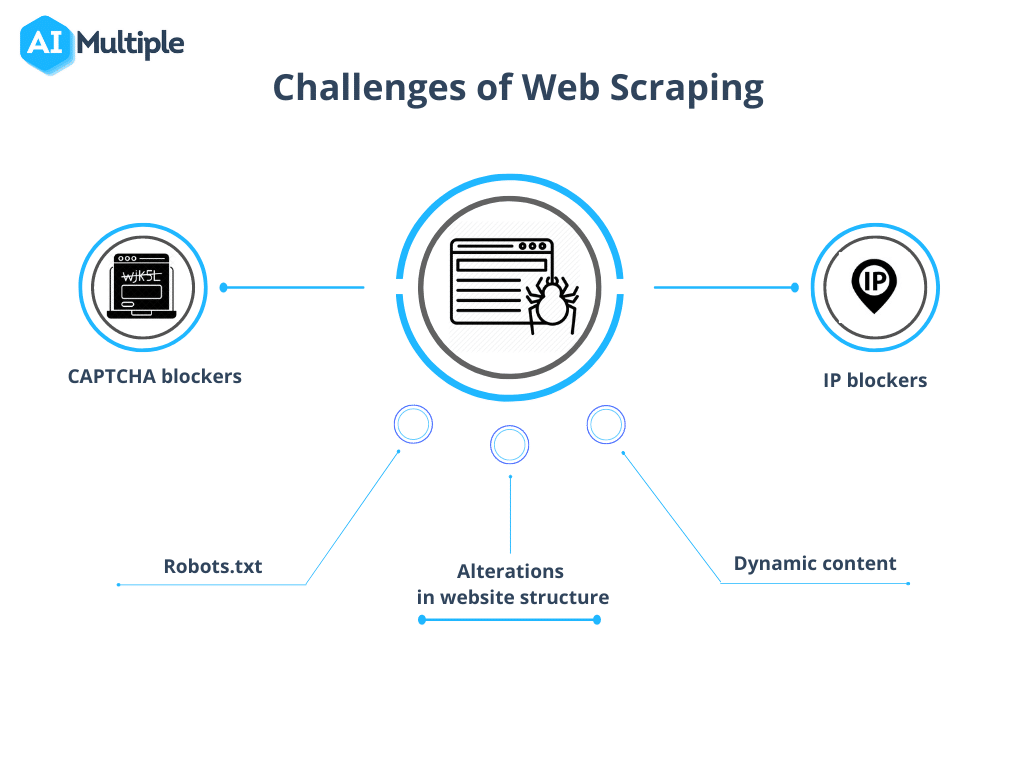
Fonte: IA Múltipla
1. Robots.txt bloqueando rastreamentos
Antes de iniciar uma indexação, é crucial confirmar as permissões do site. Se o arquivo robots.txt indicar restrições ao uso de dados de páginas específicas, é aconselhável respeitar esses termos.
2. Bloqueio de IP
Durante a coleta de dados, é essencial evitar ações que imitem o comportamento humano de forma muito precisa, pois isso pode levantar suspeitas e resultar no bloqueio do IP. Recomenda-se utilizar um breve atraso entre as requisições e empregar proxies para mascarar o endereço IP real. Também é aconselhável alternar entre diferentes proxies.
3. Armadilhas para aranhas
Alguns recursos utilizam armadilhas para rastreadores conhecidas como honeypots. Esses links ocultos no código, invisíveis para usuários comuns, podem levar um rastreador à sua detecção e consequente bloqueio.
4. CAPTCHAs
Para minimizar os encontros com CAPTCHAs, Siga as orientações fornecidas acima. Quando os CAPTCHAs forem inevitáveis, considere utilizar serviços de resolução de CAPTCHA.
5. Rastejar em excesso
Uma programação inadequada pode fazer com que um bot fique preso em um loop infinito ou realize uma busca excessiva, sobrecarregando indevidamente o site alvo. Isso pode interromper o acesso de outros usuários que precisam de recursos do site.
Resumindo: Saiba a diferença e trabalhe de acordo.
Em termos simples, o objetivo da extração de dados da web (web scraping) é coletar informações de páginas da web, enquanto o rastreamento da web (web crawling) concentra-se na indexação e localização dessas páginas. O rastreamento da web envolve a exploração contínua de links por meio de hiperlinks. Por outro lado, a extração de dados da web envolve a criação de um programa específico capaz de coletar dados de diversos sites.
Então, este blog foi útil para você? Compartilhe sua opinião e participe da nossa comunidade! Comunidade do Facebook para se conectar com outros entusiastas, e Assine nossos blogs Para mais blogs como este.