有没有想过网络爬取和网络抓取之间的区别?你并不孤单。这两个术语经常被混淆,但它们并不相同。了解区别是关键,尤其是如果你喜欢从网站提取数据。在本文中,我们将分解 网络爬取与网页抓取 详细了解。事不宜迟,让我们开始吧。

什么是网页爬行和网页抓取?
每一个搜索查询和数据丰富的网站的背后都有一个令人着迷的过程,即网络爬虫和网络抓取。这两个不可或缺的组件齐头并进,共同导航和提取有价值的信息。

来源: 研究之门
网页爬取
网络爬虫就像一个机器人探索互联网以 查找新页面。它的工作是列出所有页面。另一方面,网页抓取就像使用放大镜查看特定网站以 从某些页面获取数据。网络爬虫,又称蜘蛛程序,通常首先检查某个网站的几个主要 URL。然后,它会跟踪其他页面的链接,直到找到它想要的所有页面。
但是,网页爬取有不同的用途,例如制作网页列表和关注网站的变化。当我们想从网络上抓取信息时,网页爬取和网页抓取都很重要。
网页抓取
网页抓取涉及 从目标网站提取数据通常是使用自动化工具(称为网络抓取工具)来完成的。这些工具读取网页的 HTML 内容以提取信息。
它的工作原理如下:抓取工具首先连接到相关网页,通过网络爬取过程找到这些网页。到达那里后,它会使用 CSS 选择器等方法来选择特定的 HTML 元素 并收集所需的数据。
Web 爬取与 Web 抓取:快速概览
简单来说,网络爬取就是查找网站链接,而网络抓取就是从网站收集数据。通常,大多数涉及从网络获取信息的项目都需要抓取和抓取。
| 特征 | 网页爬取 | 网页抓取 |
|---|---|---|
| 目的 | 从网络索引和收集信息 | 从网站提取特定数据 |
| 范围 | 从网络索引和收集信息 | 关注网站内的特定页面或内容 |
| 深度 | 通常会浏览整个网站 | 针对网站内的特定数据 |
| 频率 | 定期抓取以更新搜索引擎索引 | 偶尔或根据需要提取数据 |
| 数据存储 | 存储元数据、链接和内容索引 | 提取并存储特定数据点 |
| 技术 | 通过链接发现并索引内容 | 利用 HTML 解析提取特定数据 |
| 示例 | 搜索引擎为搜索结果索引网页 | 从电子商务网站提取产品价格 |
网页抓取的通常工作方式如下:
✅ 发现 URL: 浏览网站以查找网页链接。
✅ 下载 HTML: 转到这些链接并保存网站的代码(HTML 文件)。
✅ 抓取数据: 分析 HTML 文件并挑选出您需要的数据。
因此,当网站有大量页面时,在抓取数据之前,首先要进行爬取以找到这些页面。现在,让我们更详细地了解一下网页抓取与网页爬取的区别。
网络爬取和网页抓取的不同用例
网络抓取和网络爬取是两个独立的过程,但可以有效地协同工作。它们也可以单独使用,具体取决于手头的工作。让我们来看看这两个术语的多种用例。

资源: ScrapeHero
网络爬取:最常见的用例
对于需要收集链接、缺乏特定目标且需要检索整个页面代码而无需额外解析的项目,Web 爬取非常有用。常见用例包括:
1.搜索引擎索引
- Google、Bing 和 Yahoo 使用爬虫来发现新内容和页面。
- 爬虫将信息存储在索引中,这是一个供用户检索的庞大数据库。
2. 提高网站性能
- 网络爬虫有助于分析和增强您的网站的性能。
- 检测诸如断开的链接、重复的内容或元标记问题等问题。
- 确定优化整个网站结构的机会。
3.竞争对手网站分析
- 出于 SEO 目的监控您和竞争对手网站的变化。
- 随时了解竞争对手的最新动态并及时做出反应。
4.数据挖掘
- 网络爬虫从各种在线来源收集并分析大型数据集。
- 帮助研究人员、企业或其他人获得有价值的见解。
5. 查找外部网站上的断开链接
- 检查并更新外部网站上的链接以保持准确性。
- 使用爬虫来高效的处理外部链接验证。
6.内容策划
- 爬虫可以高效地为企业或个人找到与内容相关的主题。
- 允许根据关键字或标签等特定标准进行快速管理。
网页抓取:最常见的用例
相比之下,当您有特定的数据提取目标时,网页抓取非常有用。它通常适用于:
1. 跟踪价格
- 能够自动跟踪电子商务网站上的产品价格。
- 方便快速比较多个在线平台的价格。
- 使企业能够实时了解价格变化。
2. 聚合内容
- 通过从多个来源提取相关信息实现内容聚合。
- 通过自动从各个网页收集数据来简化内容收集。
- 有助于整合不同的内容,使其可以在集中位置访问。
3. 寻找线索
- 识别并提取联系信息,简化潜在客户生成流程。
- 自动从各种在线来源收集潜在客户。
- 快速检索有价值的业务数据以识别并联系潜在客户。
5.研究社交媒体
- 提取用户评论和情绪以进行社交媒体情绪分析。
- 收集热门话题和热门帖子的数据以用于研究目的。
- 收集用户参与度指标以了解社交媒体的影响。
6. 管理网络声誉
- 监控和收集在线提及以管理和维护良好的在线声誉。
- 提取并分析有助于解决潜在声誉问题的相关数据。
- 跟踪并响应客户反馈,实现有效的在线声誉管理。
了解网络爬取和网页抓取的常见挑战
然而,网页爬取与网页抓取相比,仍存在一些需要解决的障碍。这些挑战的复杂性因项目规模而异,包括加载时间缓慢等技术障碍以及与数据隐私法相关的法律考虑。
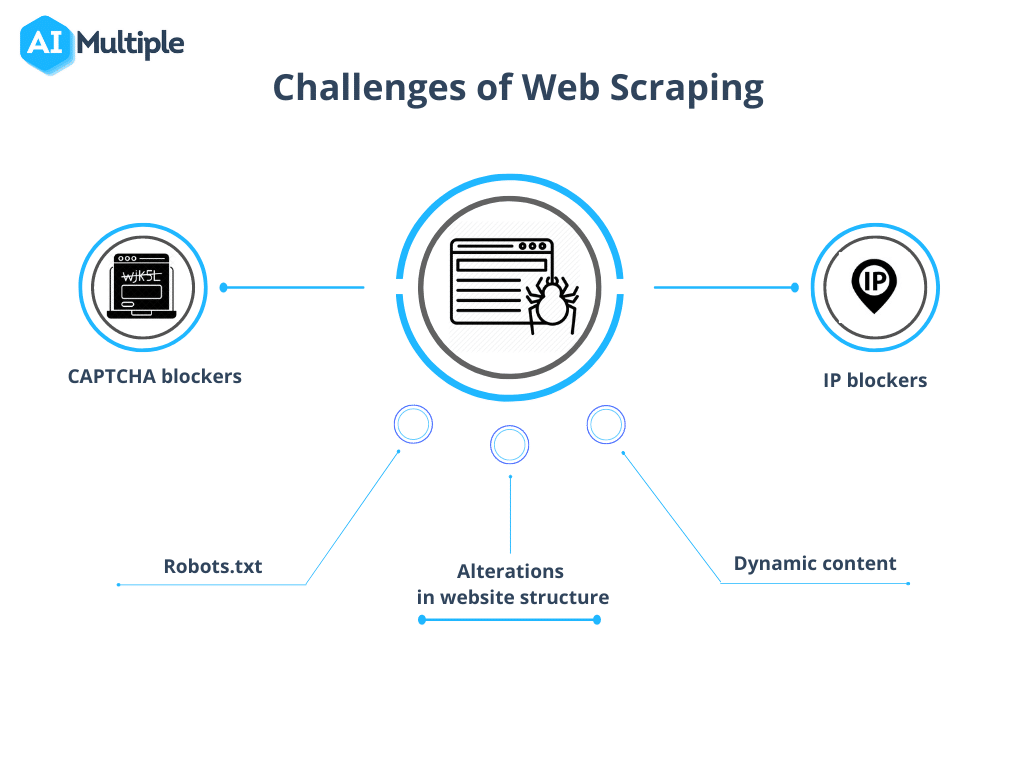
来源: 人工智能倍增
1. Robots.txt 阻止抓取
在开始抓取之前,确认网站的权限至关重要。如果 robots.txt 文件指示对使用特定页面的数据有所限制,则最好遵守这些条款。
2. IP 封锁
在爬取时,务必避免过于模仿人类行为,因为这可能会引起怀疑和 IP 封锁。建议在请求之间留出短暂的延迟,并使用代理来掩盖真实 IP 地址。还建议轮流使用代理池。
3. 蜘蛛陷阱
某些资源会使用称为蜜罐的爬虫陷阱。这些隐藏在代码中的链接对普通用户来说是不可见的,但可以导致爬虫被检测到并随后被阻止。
4. 验证码
为了尽量减少与 验证码,请遵守上述准则。当无法避免 CAPTCHA 时,请考虑使用 CAPTCHA 解决服务。
5. 过度抓取
编程不当可能会导致机器人陷入无限循环或过度抓取,从而给目标网站带来过度负载。这可能会扰乱需要该网站资源的其他用户的访问。
底线:了解差异并采取相应措施
简而言之,网络抓取的目的是从网页收集信息,而网络爬虫则专注于索引和定位网页。网络爬虫需要通过超链接不断探索链接。另一方面,网络抓取涉及创建一个能够从各种网站收集数据的独立程序。
那么,这篇博客对你有帮助吗?分享你的想法,加入我们的 Facebook 社区 与爱好者们交流, 订阅我们的博客 了解更多类似博客。